Pegasus is a project of catalog platform — Marketplace Engineering. It is one of the projects to separate catalog system out of TIKI.VN system absolutely. TIKI.VN is a big system with unclear boundary between many teams and domains. All modules share database and can access the other database directly. To scale, We have to break TIKI.VN into smaller systems, especially Catalog System — handle million products of TIKI.
Our strategy:
- First: prevent other modules to access catalog data sources directly by providing all necessary apis for both read and write
- Second: migrate data to catalog owning database and block all direct access
We have three modules:
- Mercury: replicate all changes from write side (MySQL) to read side (Mongo DB). It is the backbone to replicate all changes of products.
- Pegasus: provide read product api for all access. It is the highest throughput api of TIKI
- Arcturus: provide api to handle all inventory transactions for order placement and integrate to warehouse system
Pegasus is read product api for TIKI. TIKI.VN is an ecommerce web site, so every touch point of customer is related to product. So It is the highest throughput api of TIKI. It will prevent the direct access to Mongo DB of catalog. Pegasus has challenges:
- Reliability: handle all traffic to get product data from TIKI
- High throughput and low latency: handle at least 10k request/s, TP95<5ms
Our approach to design Pegasus is:
- Use local memory to cache product data
- Subscribe product change events from Mercury to invalid cache
- Use convenient compressions to reduce payload size, utilize cpu and network.
- Non Blocking architecture
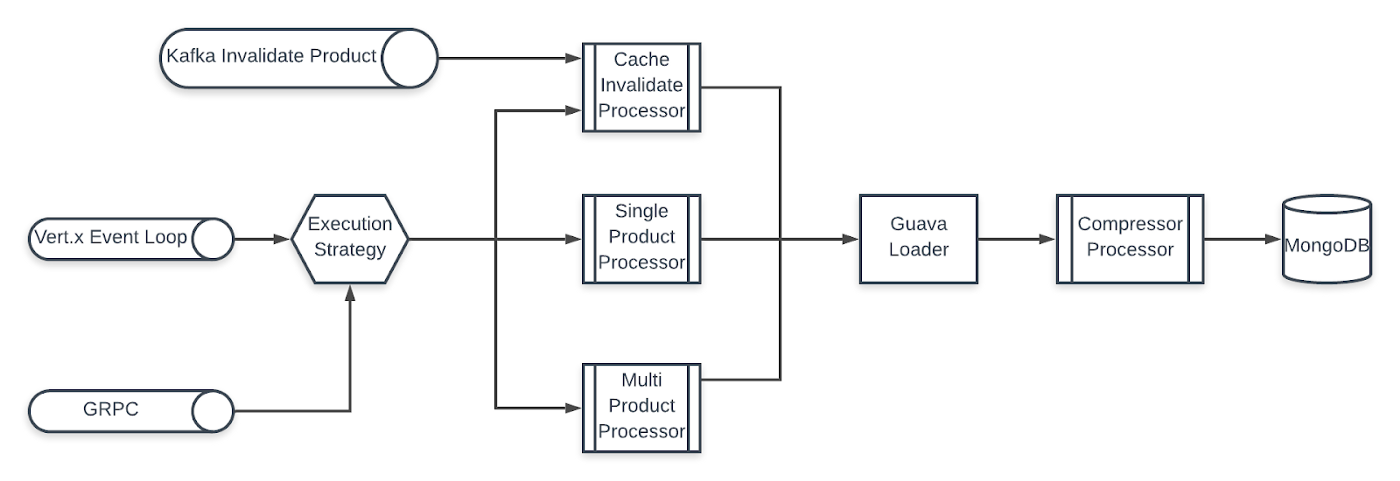
Pegasus Architecture:
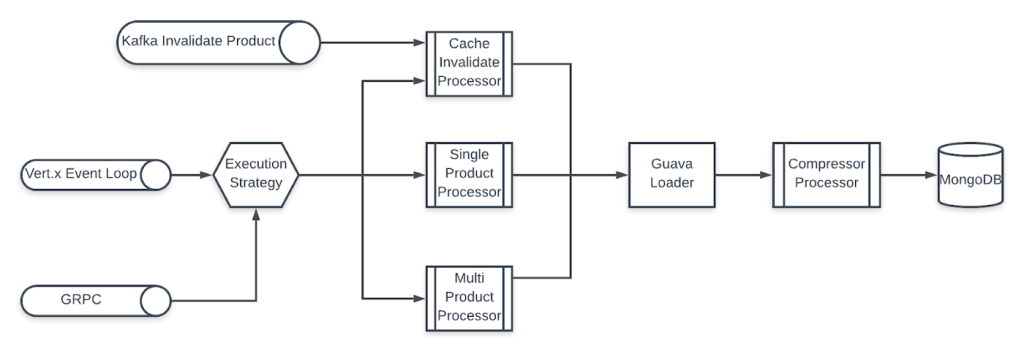
Pegasus is based on Gridgo framework and follows its architecture guideline. It consists of 3 main components:
- Entry-point: Entry to the application
- Restful API: Provides APIs for client to query/invalidate products
- Kafka Consumer: Consume messages from Kafka to invalidate products
- GRPC: Provides a wrapped GRPC layer to the API
- In-memory cache: An in-memory key value data structure to store product cache
- Compressor: A configurable compressor to compress data when storing and serving
Entry-point
Restful API
Pegasus use Vert.x connector for its Restful API. All HTTP requests start from the Vert.x internal event loop, and then are routed to one of the corresponding processors and executed with a configurable strategy. Pegasus supports the following strategies:
- default: Execute on the same thread as the event loop. This is not recommended, since although MongoDB client is asynchronous, there are still some parts of it which are synchronous, like DNS lookup. Also the compression of data will be CPU-bound, so using a single-thread will not utilize the full processing power of the CPU.
- executor: Execute the processor using Java ExecutorService. The number of threads are also configurable. Experiments show that using too many threads won’t have any particular benefit and might even slow down the application.
- disruptor: Execute the processor using Disruptor. Experiments shows that using Disruptor in this case won’t have any benefit compare to ExecutorService.
Kafka Consumer
Pegasus consume from Kafka topic index.catalog.invalidate_product, which is produced by Mercury, to invalidate the product in-mem cache. The invalidation is done by evicting the entry in the cache, the product will not be loaded until the next time it is accessed again.
GRPC
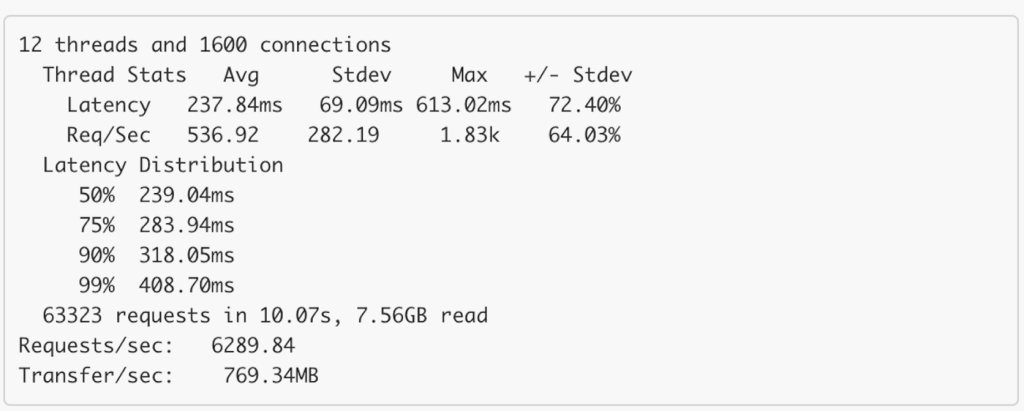
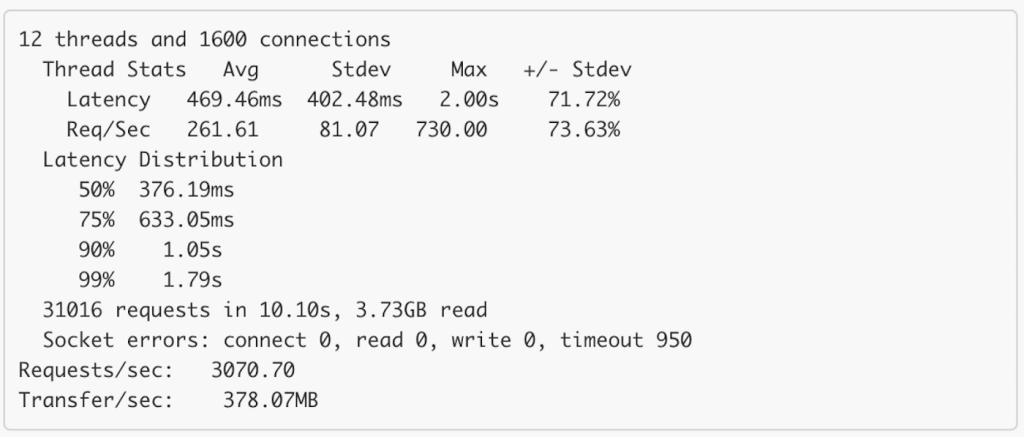
The restful API can already handle high throughput and low latency requests. Benchmark shows that with 40 opened connections, it can handle 24K RPS with TP99 of 20ms for single product API. But since most of Tala is written in PHP and PHP doesn’t have a built-in HTTP connection pool, each requests to PHP will resulted in 2 or 3 opened connections in Pegasus. Sometimes this lead to around 15K open connections and can easily overload the Load Balancer. (The L7 load balancer is not quite good, it might cut down the throughput by half and increase latency by 100%)
One nodes:
Two nodes:
It’s, however, much better with L4 load balancer:
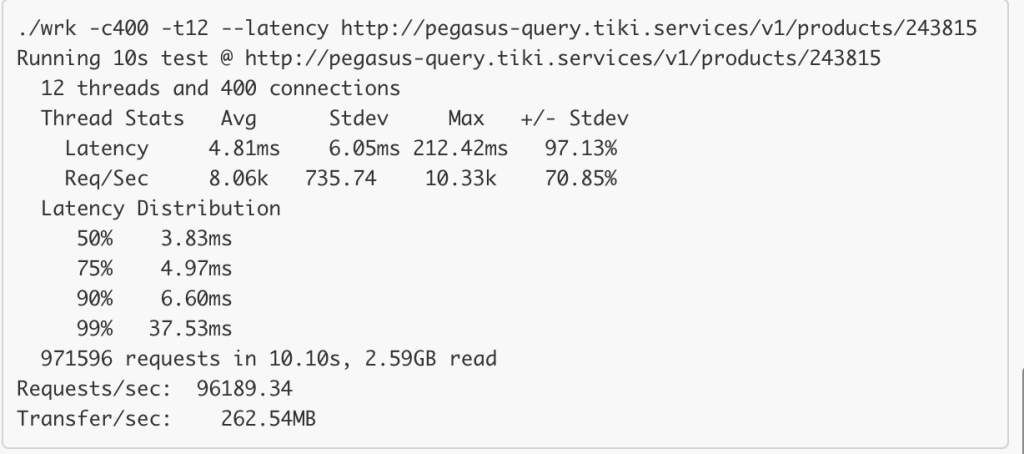
To accommodate for this lack of connection pool, Pegasus also exposes its API via GRPC, since GRPC in PHP already supports persistent connection. This is, however, not yet integrated with Tala. The response format is almost quite identical to the Restful API.
It is worth noting that using GRPC might not have any benefit with language which already supports persistent HTTP connections.
In-mem cache
Pegasus uses Guava for its in-memory product cache. This is a very simple Map from product id to product payload. The payload is usually transformed JSON (more on this under the Compressor section).
The cache is actually a series of loaders using Decorator pattern. The most basic loader is DirectMongoLoader, which queries directly from MongoDB. This loader is wrapped inside GuavaLoader, which will store the payload in Guava Loading Cache and only calls the it when cache miss happens.
For the single API, it’s very straightforward: return the payload in the cache in case of cache hit, or try to query single product from mongo when cache misses.
For the multi API, it’s a bit more complicated: query any product missing from the cache, merge with the ones already in the cache (after decompressing them), and sort according to their orders in the request, then compress before returning response to client.
There are also several optimizations in this component:
- Promise Cache: Instead of caching the actual product payload, we cache the Promise of the payload. In case of multiple threads accessing the same product ID (calling get(Long id) method), all but one of them will be blocked. To reduce the cost of context switching and have better thread management, we only cache the Promise, so the threads are only blocked as long as the Promise is being created. Generally this will be quite fast.
- Consistent Hashing: Enable consistent hashing mode in LB can increase cache hit to around 95% (from 85%). But we have now disabled it since Consistent Hashing requires extra works from LB and we cannot use a layer-4 LB.
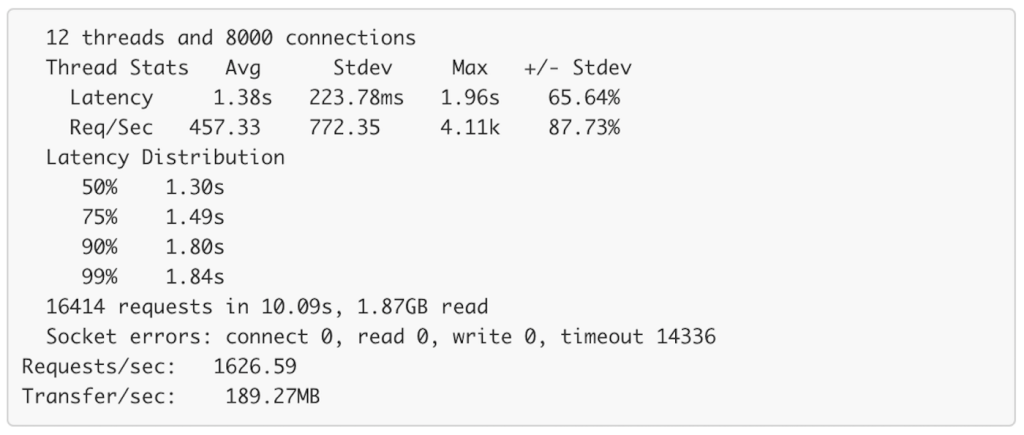
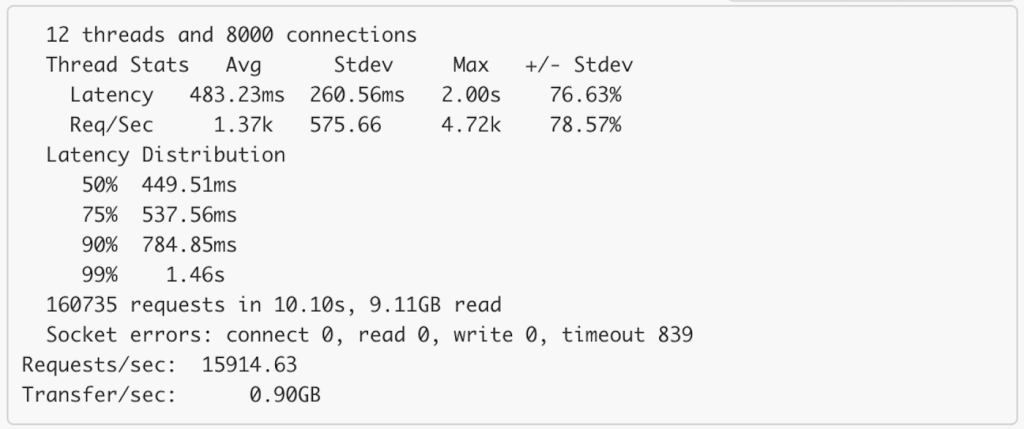
- Optionally, the GuavaLoader can also be wrapped inside OutputCacheLoader, which will store the whole response inside another Guava Loading Cache. The OutputCacheLoader will be most useful for multi-products query under heavy load. Benchmarks show that it can reduce TP90 to under 1s for a payload of 200KB with 8000 open connections. Note that the bandwidth is around 10 Gbps, and the transfer rate is around 7 Gbps (0.9 GB/s). Also keep in mind that the OutputCacheLoader is only suitable on some hot deal sales, where cache hit will be high. Generally cache hit will be quite low.
Without output cache:
With output cache:
Compressor
Pegasus supports configurable Compressors for product payload. We can configure separate compressor for single and multi query. To optimize the two APIs (single & multi), we have a separate application server for each APIs.
- To query single products: http://pegasus.xxx
- To query multi products: http://pegasus-query.xxx
Although the codebase are the same, the configuration are different for each API:
With single API, it’s better to store the gzipped payload of the products and return it directly to client, since GZIP is smaller (thus reduce payload size), and there’s no need to compress/decompress the ones already in cache.
With multi API, we can’t return the cache directly, so there’s no point keeping compressed version in the cache. Instead we only cache the plaintext version. When returning to client, compressing with Snappy is more efficient than Gzip, although payload will be increased about 2x-3x. Benchmark shows that the latency is reduced by 50% after switching to Snappy (from 15ms to 6ms).
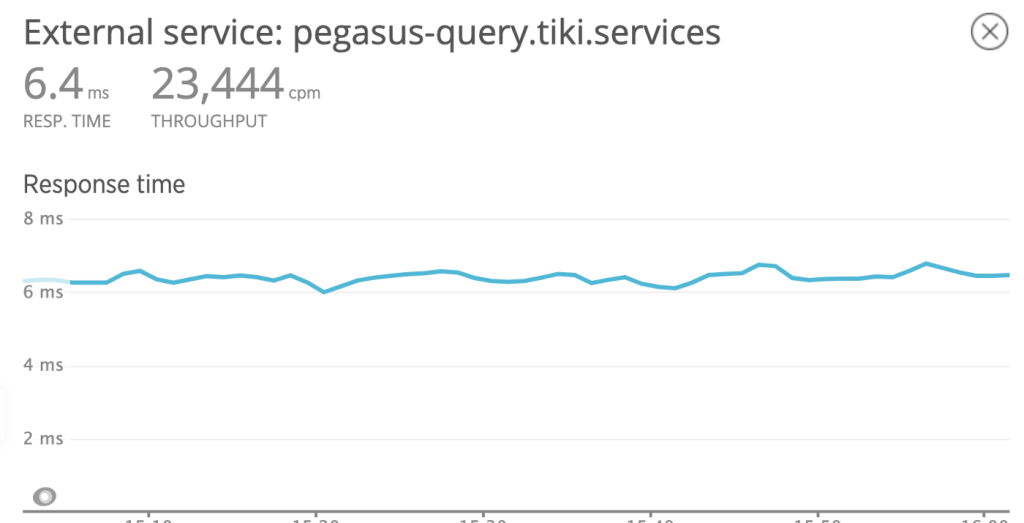
A special header will be returned to specify the compression algorithm used: compression. Client can use this information to decompress accordingly.
Performance:
Our traffic is separated into two sources: from web to render HTML and from api for Javascript or mobile app.
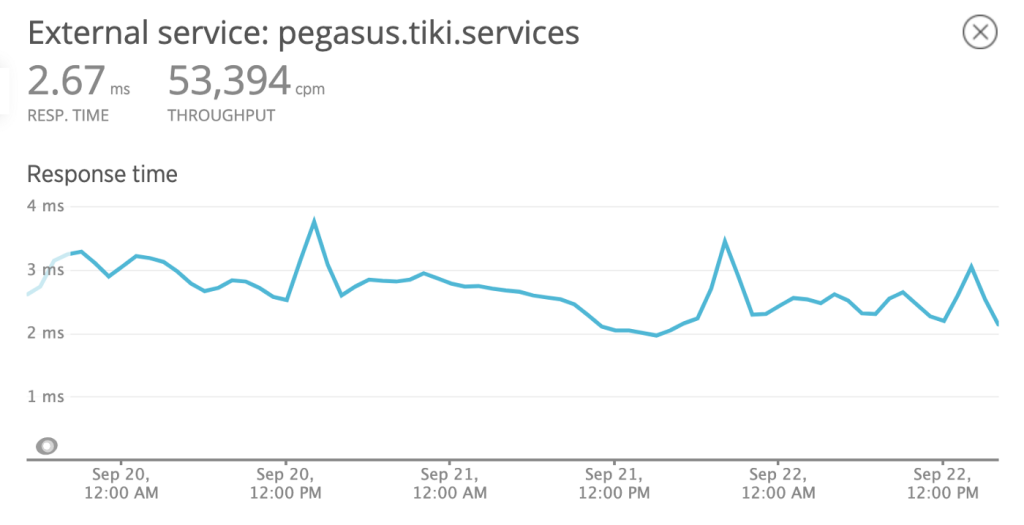
From web:
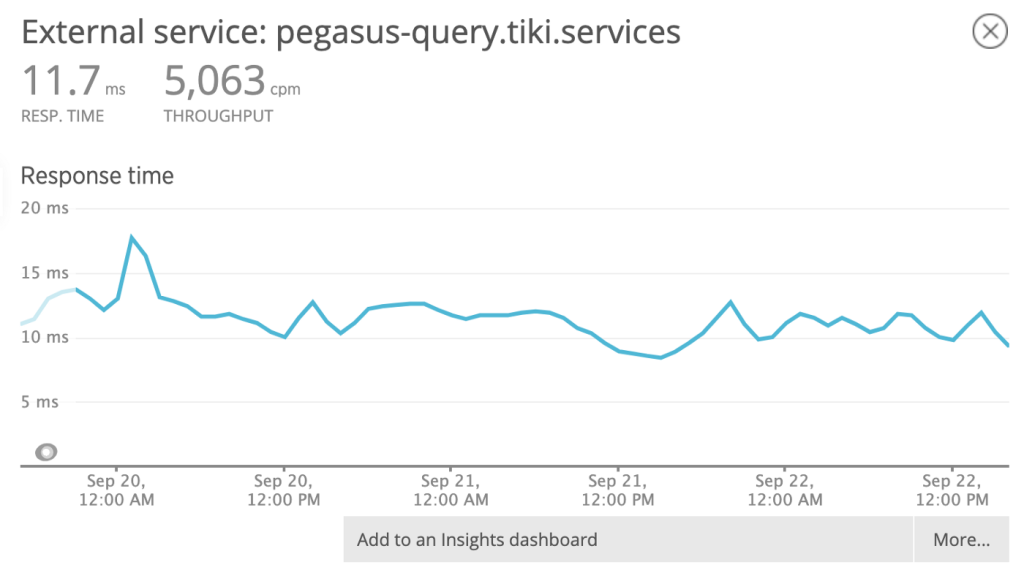
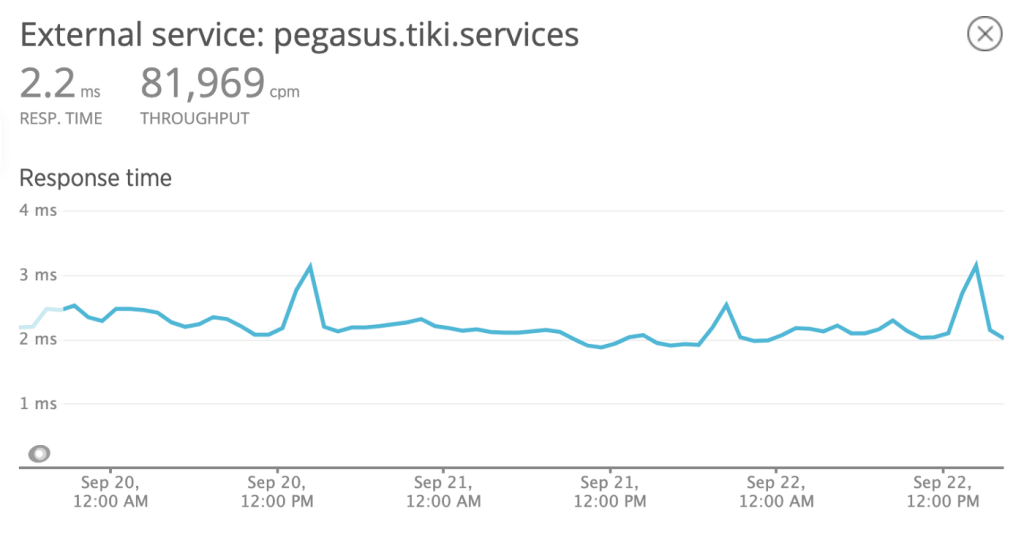
From API:
Contributors:
