1) Project definition
Business advisor aims at mapping profitable products on tiki platform to potential sellers based heavily on product sales (ie number of items sold).
For many sellers, people find it hard to get insight on the products that are trending on the market.
We want to mine our data warehouse and suggest the “best products” for sellers to start their business.
2) Seller – product matching
The question we hope to tackle in this project is a matching problem: matching between good products/keywords to potential sellers.
We propose the following matching mechanism:
Assuming we have a very good seller X, and X is actively selling 1000 products on tiki platform.
We use our data warehouse to calculate the number of items sold (we called it sales) for each 1000 products over a certain period of time (Y days – where Y is configurable)
We then rank 1000 products using the product sales. For example:
| sellerID | ProductID | NumberOfItemsSold (ie sales) |
|---|---|---|
| X | 123 | 500 |
| X | 456 | 400 |
| … | ….. | …. |
| X | 99999 | 5 |
With each of the top Z products from the above table, we use our Machine Learning algorithm to explore on the tiki pool to find similar products.
As a result, we have a pool of Z * 32 products (why 32? since we look our at most 32 similar products in the tiki pool)
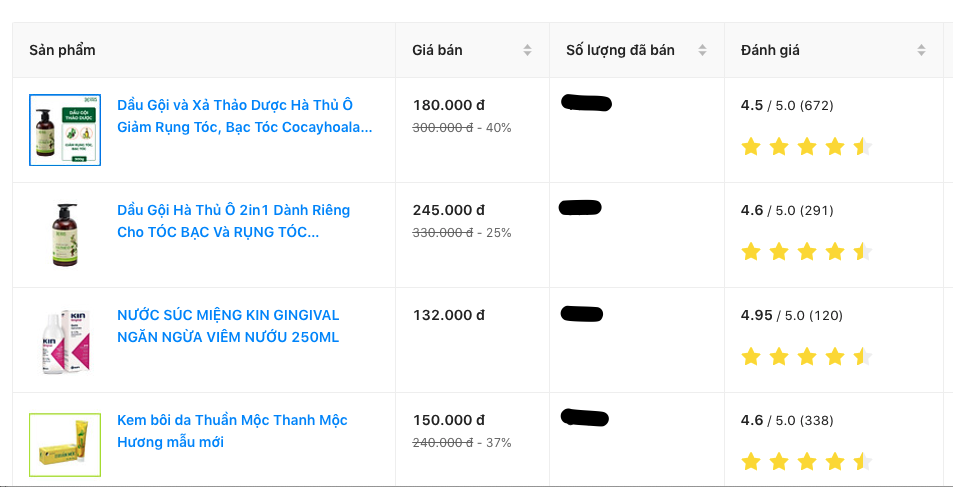
We then rank the Z * 32 pool again by number of items sold over Y days, and pick the TOP500 products as a result to suggest to seller.
The suggestion is displayed on our seller center as follow:
3) Seller – keyword matching (keyword propagation)
We also want to propose to our sellers the hot keywords that related to the product they are selling.
The matching mechanism is very similar to the seller – product matching problem.
We’ll examine the seller X again. First, we find the TopZ products of seller X that have the most sales over Y days.
We then use our data warehouse to find the keywords that our users searched and clicked on the TopZ products (let’s call the keywords K)
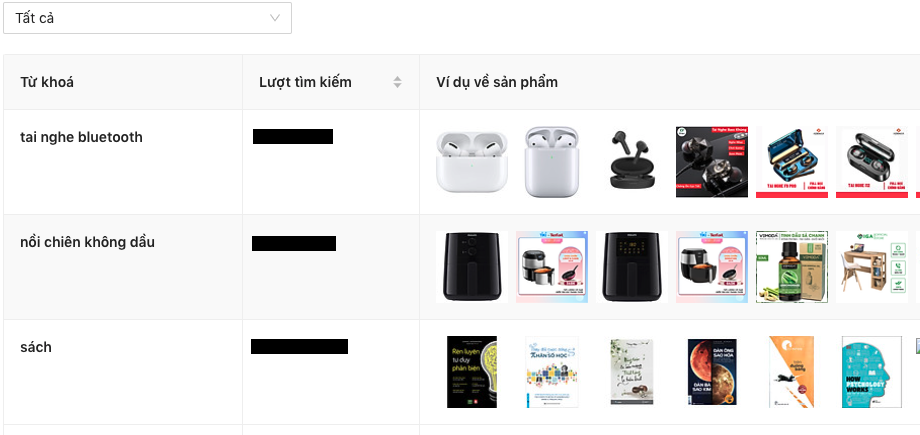
We consider K keywords related to the sellers. We then sort K keywords in terms of its searched volume over the last U days in the site, annotate the keywords with their frequently clicked items.
The ultimate result will look like below:
4) Implementation
Challenges:
The big part of the project is that we have to calculate the matching of the seller to products/keywords in the universe of all sellers in tiki.
Also, we need to calculate the items sold for every single products in the platform.
The workload needs to be updated on a daily basis so that the suggestion would not be out of date.
Also, we want the implementation has a small number of software dependencies and we want the service to be cloud native, ie it could run on container technology and manage by our Kubernetes cluster.
With all these requirement, the resource for the calculation is quite big.
Design decision:
Because of the heavy workload in calculating the matching between sellers and products/keywords, we decided to have 2 separate components:
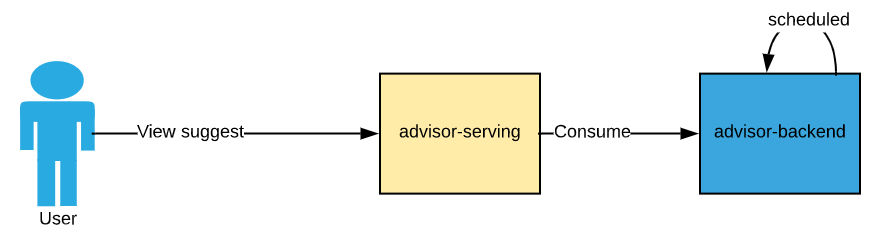
- The calculating component which is considered the “backend”. We will call this component advisor-backend
- The serving layer that would read the data backend has already calculated and display the result on our seller center. We call this component advisor-serving.
Bellow is the high level architecture design of the system. Advisor-backed is a scheduled component, meaning it will run every day at mid-night to calculate the suggestion.
We want our serving layer (advisor-serving) to run as fast as possible, we decided to store the calculation from backend site to Rocksdb.
Once the backend finished the calculation, we will transfer the Rocksdb data files to the serving layer and ensure that the serving layer stays online during this process.
This is quite a tricky engineering process. We’ll discuss this later, now let’s look at the first and most important component, the advisor-backend, our intelligent part of the system.
4.1 The advisor-backend
The implementation of our backend will rely heavily on Rocksdb, the open source key-value storage engine developed by Facebook.
We love Rocksdb since it’s fast, it’s local, no network over-head and we can fits it into our container local disk.
Therefore the backend component use Rocksdb in an embedded way, and the backend can run on Kubernetes without any problem.
We can call the component cloud native in a sense, because it doesn’t depends on external data sources. It stores its data locally, within the container.
Due to the matching approach biased over the product sales (ie number of item sold), we need to build the mapping from productID to sales.
This information will be reused in the calculation for each of the seller, so we decide to first load the mapping from our data warehouse to our local rocksDB instance.
Second, we also need to pull the mapping from sellerID to all the active selling productID from our warehouse (Bigquery, from now on, I’ll use Bigquery to refer to tiki data warehouse).
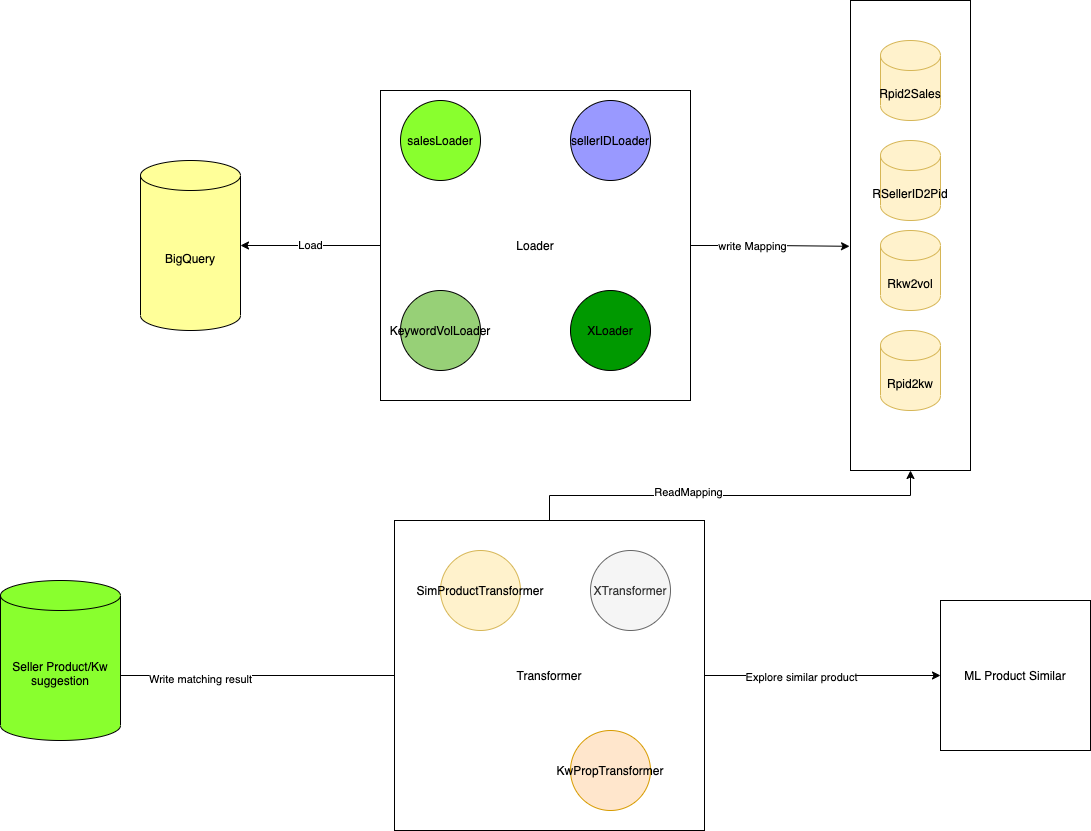
Here’s the architecture overview of advisor-backend.
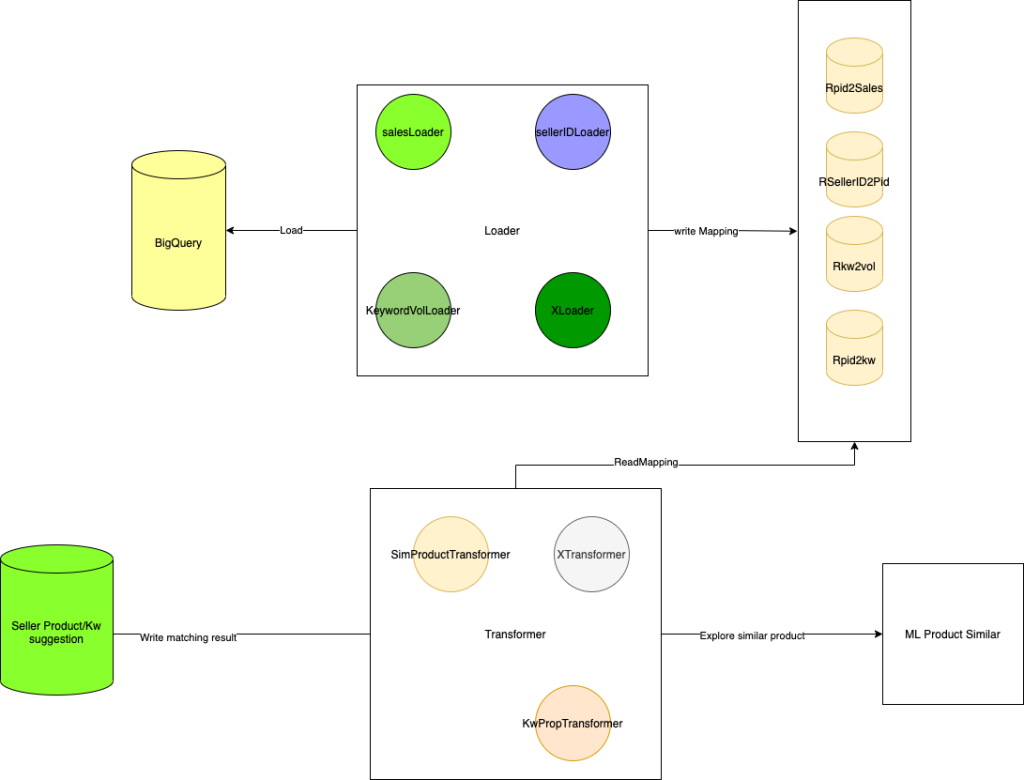
The application would have 2 main components: the loader and the transformer.
The Loader:
The loader would load the mapping from Bigquery and store to Rocksdb key-value store. Each loader would be responsible for loading specific mapping.
Currently we load the following mappings:
- salesLoader: productID to sales over a particular time window (now 6 months); result is stored to Rpid2sales
- sellerIDLoader: sellerID to active productIDs; result stored in rSellerId2Pid
- keywordVoldLoader: keyword to search volume loader
- ……
The Transformer:
After the loader finished loading data to all the mapping we need, we start to do the real mapping in the transformer.
First we iterate over all sellers and for each of the sellers, we lookup the active products that this seller is selling in the Rocksdb store.
Second, we rank these products by its sales by looking at the productId to sales mapping and choose the topZ products of this seller.
Third, for each product in the topZ set, we call our ML product similar service and try to explore the products other sellers is selling.
The result would be a set of topZ * A similar products (A is the limit of exploring each similar products)
Last, we rank the result set by the sales of the products.
We would have 2 transformer for each of the matching problem:
- The similar product transformer.
- The keyword propagation transformer.
We also plan to explore product from other sources to extends the suggestion capacity.
Final results of the transformer will be written to a dedicated Rocksdb instances. Data file of this rocksdb instances will be copy to a shared storage (NFS or Google Cloud Storage),
so that the advisor-serving can pick up and serve in our seller center application.
Schedule
We schedule the loader and the transformer job using Java Quartz scheduler. The backend job is composed by several loaders and the 2 transfomer.
The job is schedule to run at midnight and is expected to finish in early morning the next day.
4.2 The advisor-serving
The serving layer is quite simple, the component is a HTTP server that reads the suggestion data directly from RocksDB and return back to seller center.
It also cover the authorization like any other service here at Tiki. Here’s the simple overview of this component architecture
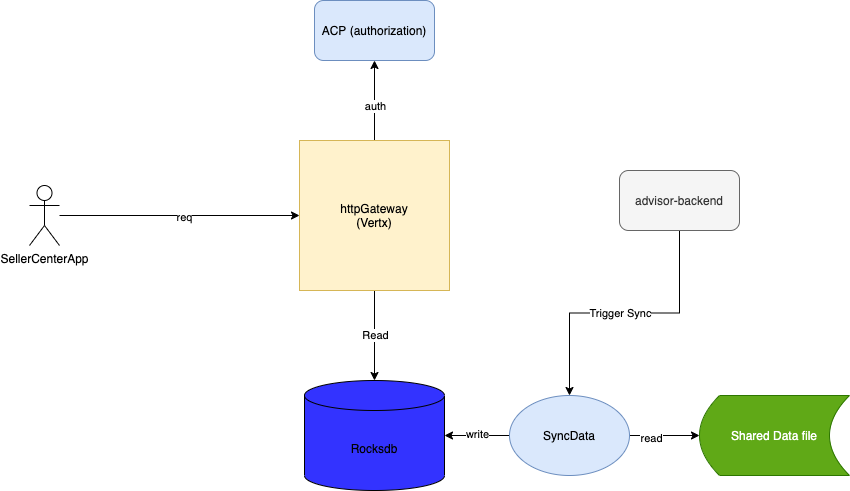
Every time the advisor-backend finished calculating the matchings, it will signal a synchronization message to a Redis pub/sub channel.
The SyncData component subscribes for this channel, whenever the calculation finished, it will copy Rocksdb data files from the Shared Data File location to the local Rocksdb instance.
Also, at start-up of the application, the SyncData component also copy data from the shared data file.
The copy data process is quite time consuming, it took around 5 minutes to finished copying the data.
To keep our service online during this process, we setup the Kubernetes workload with the health-check API endpoint.
Whenever the health-check endpoint is ready, the k8s pod would be considered ready to accept traffic.
5. Result
With some engineering tweak, our system is quite fast and resilient. The backend processes matching products for 29,788 sellers and matching keywords for 36,278 sellers
The quality of matching algorithm is quite promising, we barely see any abnormal suggestion.
For example, if the seller is a book store, we would suggest hot/trending books and office utilities product.
Runtime for each matching job is ranging from 4 hours to 6 hours, thanks to Rocksdb.
We cache many calculation so that the process is not run the same calculation for two different sellers.
Also, the backend is setup by running one single Kubernetes pod. We launched the project for around 3 months and there’s no incident reported, this saves us a lot of operation resource.
We store the suggestion in Rocksdb with byte array format. Therefore in the serving layer, the application would just return the byte array directly to client, there is no serialization/deserialization cost.
This makes the serving API is very fast despite the fact that the suggestion payload is very big.
For example, one request payload size is 1.16MB took only 282 ms to load data, it’s near the download speed of big file over internet.

Lesson learn is that with consistent engineering design, we can achieve very good performance.
6. Road-map (akka Todo)
- Monitor quality of suggestion: use kafka to record seller action; store to bigquery log table
- Integrate with suggestion from other data science algorithm instead of just Product Similarity
- Suggestion should be more dynamics: ie change more frequently
PS: happy reading! We’re hiring, check our job description here: https://tuyendung.tiki.vn/job/senior-data-engineer-seller-center-1874