Như mọi người biết, một công ty thường sẽ có rất nhiều metrics để theo dõi tính hiệu quả của các projects mà công ty đang xây dựng. Một trong những metric quan trọng đối với e-commerce là traffic cụ thể hơn là session. Nói nôm na traffic là số lượng phiên khách hàng truy cập vào website. Vậy vì sao traffic (session) lại quan trọng như vậy?
Chỉ số này sẽ giúp biết được có bao nhiêu khách hàng đến từ những nguồn nào. Ví dụ khách hàng có thể vào trực tiếp website Tiki để tìm kiếm sản phẩm và mua sắm (còn gọi là direct channel), hoặc khách hàng có thể thông qua các công cụ tìm kiếm như Google hay Bing, Yahoo dẫn vào trang Tiki hay là khách hàng sẽ nhìn thấy các sản phẩm đến từ các kênh quảng cáo như Google Ads, Facebook Ads và Affiliate networks (Paid channel),… Cùng với chỉ số doanh thu của từng kênh, công ty có thể biết hiệu quả của từng kênh để đầu tư một cách chính xác và có chiến lược phù hợp để phát triển.
Đọc qua thì thấy con số này nghe hay cho business team xem, vậy còn những bạn làm data thì liên quan gì đến con số này? Để có thể hình dung rõ hơn mình xin được đề cập một usecase cụ thể. Ví dụ một ngày đẹp trời nọ, team marketing đến hỏi bạn X (data analyst): “X ơi thử xem giúp chị xem những sản phẩm này nào đang hot, bán được nhiều nhỉ, chị vẫn còn budget để đẩy mạnh chạy ads hơn cho những sản phẩm này?”
Lúc này vai trò của data analyst (bạn X):
- X sẽ bắt đầu phải đi xem những thông số liên quan ví dụ như GMV, NMV qua các giai đoạn, khuyến mãi, các chỉ số về traffic, conversion rate (tổng số đơn chia cho số lượng session đi qua những sản phẩm này).
- Tuỳ từng hệ thống data đã phát triển đến mức nào mà workload của X sẽ nhiều hay ít. Nếu hệ thống chưa đủ tính năng thì lúc đó X sẽ phải đi viết SQL rồi lấy ra data thô đưa vào model để tính toán những sản phẩm nào tốt. Nếu đã có sẵn hệ thống tốt thì X chỉ việc kéo thả là có được dữ liệu để làm model hoặc là implement thẳng model vào hệ thống sau này chỉ cần thao tác vài nút nhấn là biết cái nào tốt rồi không phải mất quá nhiều thời gian để viết SQL. Còn nếu chưa có cả hệ thống lẫn X thì thôi chị lên tạm GA mà xem số rồi chờ team phát triển hệ thống để có thể cover những tính năng mà GA chưa thật sự tốt.
Vai trò của bạn backend engineer Y (data engineer):
- Y ơi, có gì giúp X lấy ra mấy số này với. Có cái session là hơi khó.
- Y sẽ phải đi học cách tính và build hệ thống để tính ra session và từ session ra doanh thu của các kênh (direct channel, search, affiliate,… ).
- Y cũng sẽ phải hiểu thêm về cách chạy marketing. Ví dụ lên Google search keyword là “iPhone 12”. Rồi thấy quảng cáo click vào thì thấy ngày 1 đường dẫn như thế này: https://tiki.vn/dien-thoai-iphone-12-64gb-hang-chinh-hang-den-p123345348.html?spid=70766417&utm_source=google&utm_medium=cpc…
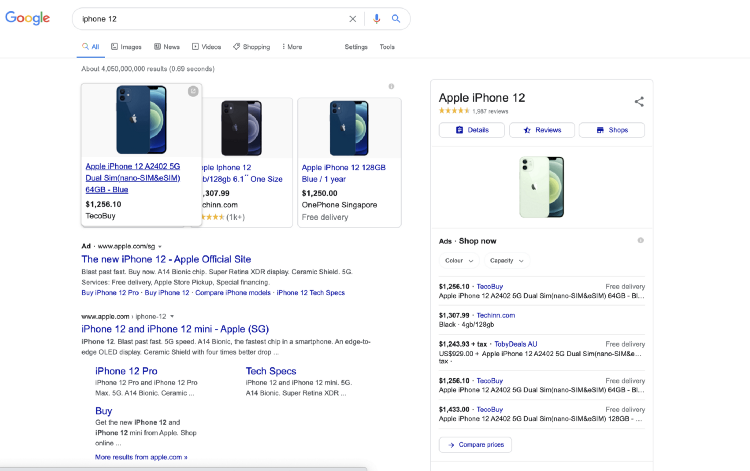
- Y sẽ phải nhìn thấy đường dẫn này sẽ có cái param utm_source, utm_campaign,… Vậy là click này đã sinh ra một session mới khi đi vào hệ thống đến từ Google. Nếu click vào mà mua hàng thì tiền từ cái đơn iphone sẽ được tính cho Google channel.
- Y tiếp tục phải biết trong 30 phút mà có hành động gì thì vẫn tính là 1 session còn nếu không có hành động gì thì session sẽ bị expired và khi vào lại sẽ sinh ra 1 session mới. Cũng như biết khi qua ngày mới thì session cũng tự tạo mới và khi đổi kênh thì session cũng được tạo ra mới.
Ngoài ra Y còn phải build hệ thống để lưu trữ luôn những cái param như utm_campaign để có càng nhiều số càng tốt. Và hiểu sau mỗi ký hiệu đó là gì. Vậy nếu click vào 1 cái quảng cáo 60 ngày trước thì revenue đó vẫn tính cho click đó à? Lúc này sẽ phải hiểu thêm attribution model để bao nhiêu là hợp lý, windows time của attribution này là bao lâu vì 60 ngày lâu quá, ảnh hưởng rất nhiều đến cách công ty invest.
Bài toán sẽ không dừng lại ở đó vì user không chỉ tương tác ở một nền tảng mà có thể tương tác ở rất nhiều nền tảng khác nhau. Ví dụ chẳng hạn bạn có thể thấy sẽ có một tập user tìm kiếm sản phẩm trên điện thoại và mua hàng trên máy tính bảng trong cùng 1 ngày nhưng lại có một tập user khác click vào ad trên điện thoại hôm nay rồi đóng lại, ngày tiếp theo họ mở trang web trên máy tính xem sản phẩm và rồi sau 1 thời gian cân nhắc thì có thể là 2 ngày sau họ mới quay lại mua sản phẩm đó bằng máy tính bảng chẳng hạn. Lúc này việc tính toán session cross device sẽ giúp liên kết được dữ liệu từ nhiều thiết bị và hoạt động của người dùng từ rất nhiều session khác nhau giúp ta xây dựng nên một bức tranh toàn cảnh về thói quen của khách hàng và họ sẽ làm gì trong từng giai đoạn của quá trình chuyển đổi conversion — từ đó giúp ta giữ chân được những khách hàng tiềm năng này thành khách hàng thân thiết.
Tiếp đến Y sẽ nghĩ về việc build cái hệ thống ngày handle cả tỷ events và lại độ trễ là gần như không có (vài giây là có số rồi). Nhưng bù lại Y sẽ hiểu hơn về business hiểu cách vận hành và có thể build 1 cái thay Google Analytics để phục vụ mở rộng tính năng.
Bên cạnh đó, việc tính toán traffic session không chỉ phục vụ cho vấn đề marketing của business team mà còn là nền tảng để giải quyết những bài toán thử thách phát sinh khác như:
- Fraud Detection Service để phát hiện những hành vi gian lận như cheat coupon, bom đơn hàng, mua sỉ,…
- Coupon Delivery Service cho user chẳng hạn như coupon chào bạn mới, coupon cho ngành hàng mà user quan tâm.
- Customer Dataplatform.
- Hệ thống tiếp thị liên kết (Affiliate System).
Từ những thử thách kể trên, đội ngũ kỹ sư team data của Tiki đã phát triển một hệ thống tính toán session realtime mang tên Observer với thiết kế kiến trúc có thể dễ dàng scale ngang từng service độc lập, chịu được tải tốt đáp ứng được lượng traffic khổng lồ trong những đợt peak event như 11.11, Black Friday,…

Kiến trúc hệ thống
“Everything should be made as simple as possible, but not simpler.“
— Albert Einstein
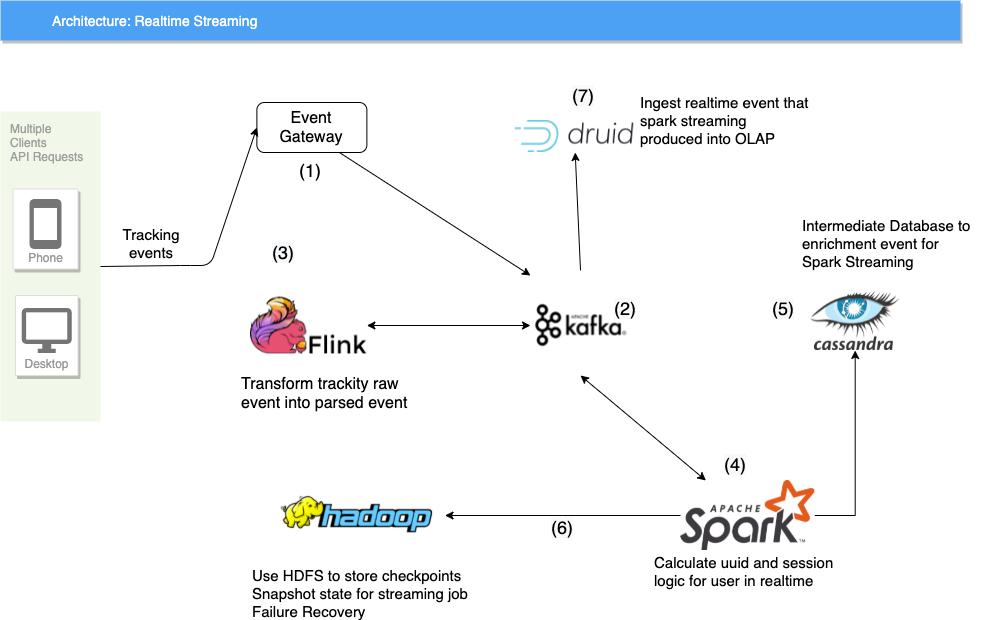
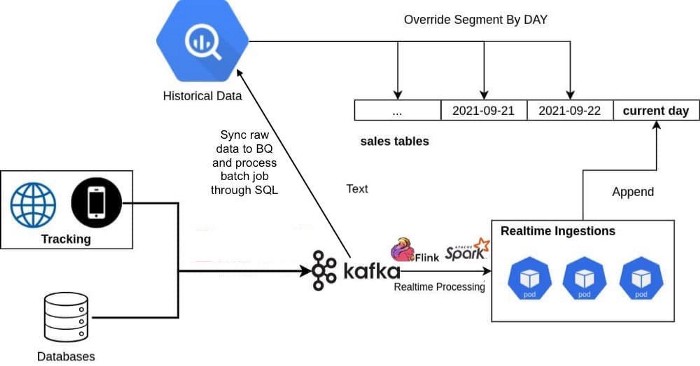
Hình trên minh hoạ kiến trúc các thành phần trong hệ thống realtime data platform của Tiki. Chúng ta sẽ lần lượt đi qua từng phần của hệ thống.
(1) Đầu event gateway làm nhiệm vụ tracking lại lượng traffic truy cập vào Tiki trên các nền tảng, web, mobile web, android và iOs sau đó các data này xuống Kafka (2) vào topic raw event (tạm gọi là topic A). Mỗi hoạt động của khách hàng sẽ được ghi lại trong hệ thống như một transaction xuyên suốt thời gian sử dụng và khách hàng sẽ được định danh bằng user id để phục vụ cho việc tính toán cross device.
Do (1) chỉ đảm nhận nhiệm vụ collect log nên sẽ không sẽ xử lý bất kỳ logic nào trên data mà chỉ đơn thuần shift and forget everything. Lúc này topic A sẽ có rất nhiều event không đúng format đã quy định. Bên cạnh đó cũng cần phải enrichment thêm một số field dữ liệu trước khi xử lý logic tính toán, ví dụ như user bỏ một món hàng vào giỏ hàng có event add_to_cart thì chỉ có product_id, chúng ta phải cần enrichment thêm giá trị category, name, seller id,… lúc này (3) sẽ làm nhiệm vụ kể trên.
(3) là một service Flink sẽ parse và enrichment tất cả những event được whitelist theo event name (chỉ consume những event liên quan đến behavior của người dùng). Event nếu parse thành công sẽ được bắn ngược lại một topic khác của Kafka (2) (tạm gọi là topic B-1), nếu parse thất bại sẽ bắn raw event đó kèm vs message xử lý lỗi của flink về topic B-2.
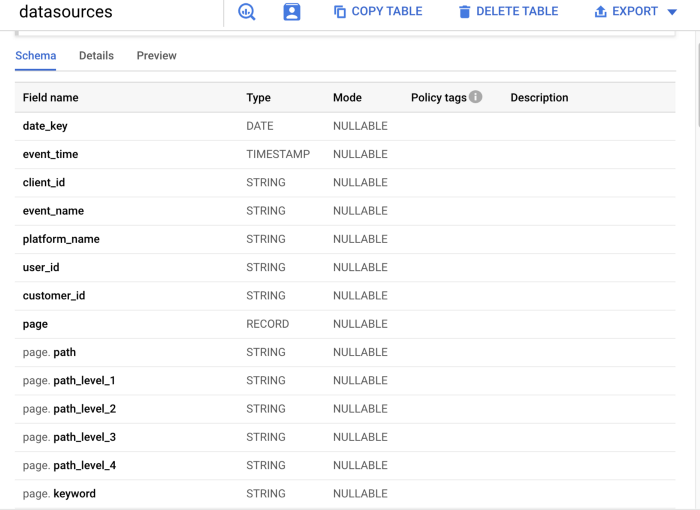
(4) là linh hồn của toàn bộ hệ thống realtime streaming. Service này sử dụng Spark có nhiệm vụ tính toán session, attribution cho đơn hàng, lượng CCU, new user,… với cross device (nghĩa là user có thể vừa sử dụng web vừa sử dụng app nhưng vẫn tính cho cùng 1 session). Cách tính session tương tự như GA với 3 rule chính:
- Session thay đổi khi qua ngày mới.
- Mỗi session tối đa là 30 phút.
- Nếu utm params thay đổi thì session sẽ được tính theo attribution model là last click non direct với windows time là 3 ngày.
Last click non direct là model bỏ qua direct traffic và tính 100% attribution của order cho channel cuối cùng được customer click vào trước khi mua hoặc chuyển đổi. Model này phù hợp với business e-commerce như Tiki. Để có thể tính toán và hợp nhất tất cả session của user thông qua cross device thì chúng ta cần phải xác định được user id. Vậy user id là gì?
Nhiều hệ thống phân tích không thể định danh được cùng 1 user duy nhất đang sử dụng nhiều thiết bị hoặc session vì vậy những hệ thống này sẽ ghi nhận là một user mới vào cho mỗi lần một người chuyển thiết bị khác hoặc bắt đầu một session mới. Vì lý do đó, khi khách hàng đăng nhập và được định danh trong hệ thống sẽ sinh ra một chuỗi kí tự cố định duy nhất đại diện cho khách hàng đó trong hệ thống và user id này sẽ tương tác dữ liệu với một hoặc nhiều session được khởi tạo từ một hay nhiều thiết bị khác nhau. Với user id chúng ta có thể xác định được những hành động liên quan trên những nền tảng khác nhau với những điểm dữ liệu độc lập không liên kết với nhau. Ví dụ một từ khoá tìm kiếm trên điện thoại, hành vi mua hàng trên laptop và quay lại tương tác bằng máy tính bảng dường như không liên quan gì đến nhau nhưng giờ đây với user id được xác định thì chúng ta có thể có cái nhìn toàn cảnh về cách mà user tương tác với business hiện tại cũng như cá nhân hoá các trải nghiệm người dùng có được từ hệ thống.
Ngoài ra khi tính toán session chúng ta cũng phải cần lưu ý về session unification (hợp nhất session) của hệ thống. Session unification là việc ghi nhận lại session của user được xác định trước lúc user thực hiện việc đăng nhập.
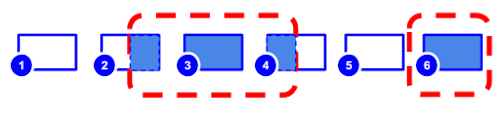
Ở hình minh hoạ dưới, mỗi session sẽ được biểu diễn bởi hình chữ nhật và con số thể hiện các session khác nhau của người dụng. Những phần tô màu trong hình chữ nhật biểu diễn thời gian user đăng nhập vào hệ thống và đã được định danh. Ví dụ, user id được gán vào cho toàn bộ session 3 và 6 nhưng chỉ ở 1 phần ở session 2 và 4. Những đường gạch đỏ đứt đoạn biểu diễn những sessions (hoặc 1 phần session) được liên kết với nhau thông qua cùng 1 user id được định danh.
Không có session unification
Có session unification
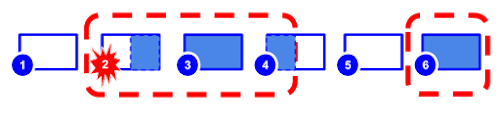
Session unification chỉ được tính toán và correct ở batch job vào cuối ngày còn với realtime thì chúng ta không thể tính session unification này nên sẽ có độ lệch session nhất định giữa realtime và batch job là do cơ chế này. Đây là mô hình Lambda Architecture được áp dụng trong rất nhiều hệ thống Big Data hiện tại.
Quay trở lại với bài toán tính toán session với last click non direct model ở trên, trong quá trình tracking chúng ta sẽ chia làm 2 loại event: identify và behavior tracking. Event identify sẽ là event định danh việc user có đang login hoặc logout trong hệ thống hay không. Event behavior tracking là một loạt các event ghi lại các hành động của người dùng như tìm kiếm (search), xem một sản phẩm (view), thanh toán (checkout) và mua hàng thành công (purchase) hoặc mua hàng thất bại (checkout fail). Tất cả các event được định danh bằng trường client_id (web, mweb) hoặc device_id (android, ios), duy chỉ có event identify sẽ có thêm customer id của tài khoản khách hàng đã đăng nhập.
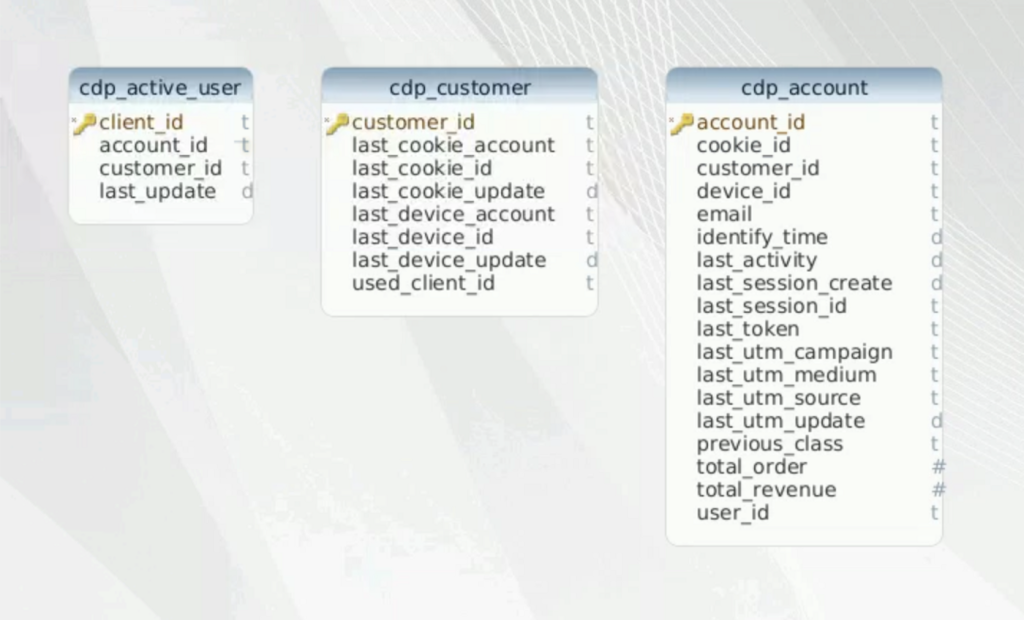
Để tính toán được logic session trên hệ thống sử dụng Cassandra (5) để làm database trung gian lưu trữ toàn bộ thông tin metadata dimension về người dùng trên hệ thống (ví dụ client_id nào vừa đăng nhập, những thiết bị mà người dùng từng sử dụng, utm source,…). Ta sẽ có lần lượt 3 bảng sau:
- cdp_active_user: mapping client_id với customer_id gần nhất trên thiết bị mà user đang sử dụng.
- cdp_account: lúc này account id sinh ra là id định danh kết hợp khi một thiết bị (client_id/device_id) được đăng nhập trên một tài khoản nào đó (customer_id). Trên account id này sẽ lưu lại toàn bộ thông tin về session cũng như utm params trong phiên làm việc gần nhất.
- cdp_customer: mapping customer_id với account_id của client_id và device_id gần nhất đang được đăng nhập bởi user.
Ví dụ cho một phiên làm việc cross-device của user (lưu ý toàn bộ các record trong bảng đều unique bởi id (client_id, customer_id và account_id) và update liên tục theo thời gian nên ví dụ dưới đây chỉ mô tả cách tính toán session của user theo thời gian, không phải là dữ liệu lưu thực tế trong bảng):
- User mở trang Tiki trên web (chưa đăng nhập).
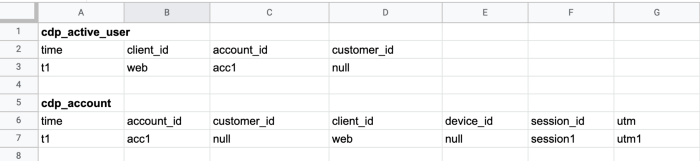
2. User đồng thời mở app Tiki trên điện thoại (chưa đăng nhập).
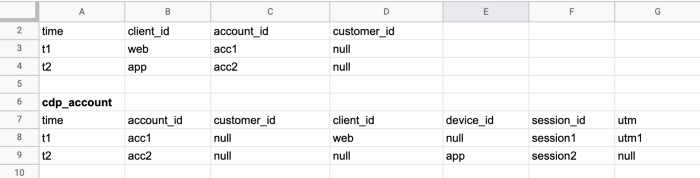
3. Sau một thời gian sử dụng thì user quay trở lại đăng nhập trên app.

4. Sau đó user cũng đăng nhập trên website Tiki với cùng tài khoản trước đó đã sử dụng trên app.
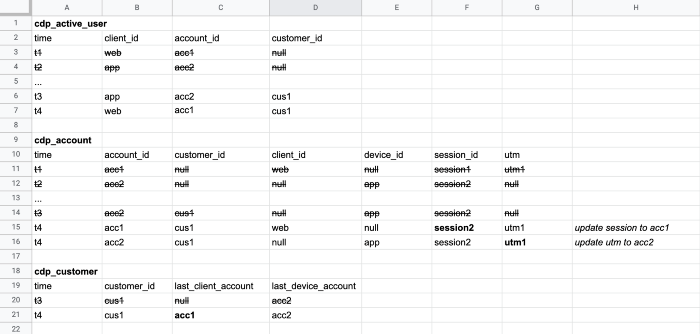
5. Lúc này session và utm sẽ được đồng bộ cho cả web và app cho user.
(4) dùng cơ chế client mode chạy trên K8s nên dễ dàng scale số lượng executor để chạy job.
(4) consume data input từ topic B-1, tính toán và sẽ bắn output ngược lại Kafka với topic event session (tạm gọi là topic C).
(6) Hadoop được setup theo cơ chế HA mode để lưu trữ metadata là các checkpoint partition Kafka đã consumer bởi Spark (4). Nếu (4) bị lỗi thì sẽ được restart và load chạy tiếp từ những checkpoint này.
(7) Druid là OLAP database sẽ consume từ 2 topic là topic B-2, mục đích là monitor lượng log parse bị lỗi từ (3) và topic C để monitor toàn bộ session, số order và NMV,…
Toàn bộ những service nói trên đều được chạy trên k8s cluster và có thể scale độc lập để đáp ứng được lượng traffic khổng lồ trong những đợt peak event.
Tại sao lại sử dụng Spark thay vì Flink cho toàn bộ hệ thống realtime
“Choosing right tool for right job.”
Đây luôn là câu hỏi mà mọi developer đặt ra khi sử dụng bất kì công nghệ nào. Chắc hẳn tới đây sẽ có bạn đặt câu hỏi: tại sao lại không sử dụng Spark hoặc Flink cho toàn bộ hệ thống mà lại sử dụng cả 2. Đã có rất nhiều bài so sánh về 2 framework realtime streaming này mà trong giới hạn bài viết này sẽ không so sánh lại chi tiết nữa.
Spark streaming có cơ chế là micro batch tức là với load message thành từng batch nhỏ liên tục trong khi đó Flink là realtime operator based computational model. Với spark streaming do cơ chế micro batch load lên nên nếu có bất kì worker chưa process xong partition thì buộc tất cả phải cùng đợi để xử lý xong rồi mới load micro batch tiếp theo. Còn với Flink thì nếu worker nào xử lý partition xong thì sẽ tiếp tục load message của từ partition đó và xử lý liên tục.
Ví dụ ở service (4) để tính toán session, giả sử ta có user A vừa sử dụng web (tạm gọi là client_id 1) và app (tạm gọi là client_id 2) đồng thời tại 1 thời điểm t. Topic C có 3 partition và service 4 cũng có 3 worker để consume 3 partition này cùng lúc. Vậy nên giả sử client_id 1 và client_id 2 nằm trong 2 partition (tương ứng parition 1 và parition 2) khác nhau. Giả sử event client_id 2 đến sau client_id 1 khoảng một vài phút thì ở Flink có khả năng load event client_id 2 lên trước do partition 2 xử lý nhanh hơn partition 1 nhưng với spark thì do load cơ chế micro batch và phân phối lần lượt nên event session sẽ luôn tính đúng. Ở đây mặc dù Flink có hỗ trợ cơ chế state nhưng event buộc phải sink xuống Kafka liên tục không được giữ lại quá 10 phút (realtime) và khó khăn cho việc xử lý logic ở Cassandra database (5) nên lựa chọn Spark là giải pháp tối ưu cho service (4) này
Ngược lại ở service (3) do chỉ đảm nhận nhiệm vụ parse và enrichment mà không cần quan tâm thứ tự trước sau của event nên cơ chế Flink phù hợp hơn vì đáp ứng được tốc độ parse và enrich nhanh của dữ liệu cũng như không bị bound up bởi logic tính toán và query quá phức tạp từ database khác.
Kết lại
Big data đã, đang và vẫn sẽ là xu hướng tất yếu trong tương lai cũng như là hướng đi nòng cốt mà Tiki xây dựng. Rất cảm ơn mọi người đã đọc blog và chia sẻ, team data của Tiki hoan nghênh mọi ý kiến đóng góp, đánh giá từ mọi người.

Ở ngôi nhà Tiki, chúng tôi luôn tiếp tục không ngừng học hỏi, tìm kiếm những giá trị mới. Mỗi thành viên là một viên gạch góp phần xây dựng nên những giá trị cho cộng đồng và tạo nên sự thay đổi. Vì vậy, Tiki luôn chào đón những con người muốn đồng hành cùng tạo nên giá trị đó. Hãy ghé thăm https://tuyendung.tiki.vn với rất nhiều vị trí và cơ hội đang chờ đón bạn thử thách. Build together, grow faster. ✌️
Contribution
Special thanks to my colleagues for helping me write this article.
@hoang.ho@tiki.vn
@hien.pham@tiki.vn
@toan.nhu@tiki.vn
Bài viết quá hay và chi tiết, sẽ bookmark và đọc lại. Cảm ơn 3 bạn đã chia sẻ.
Mình có một câu hỏi về giải pháp này. Nếu CTY mình vẫn còn nhỏ và chưa cần đến realtime solution như Tiki thì các bạn có thể chia sẻ một giải pháp nào đơn giản hơn để tận dụng tốt dữ liệu từ Google Analytics để tăng trải nghiệm khách hành?
Cảm ơn!
Cám ơn bài chia sẻ của các bạn.
Không có tiếng Việt hả ad