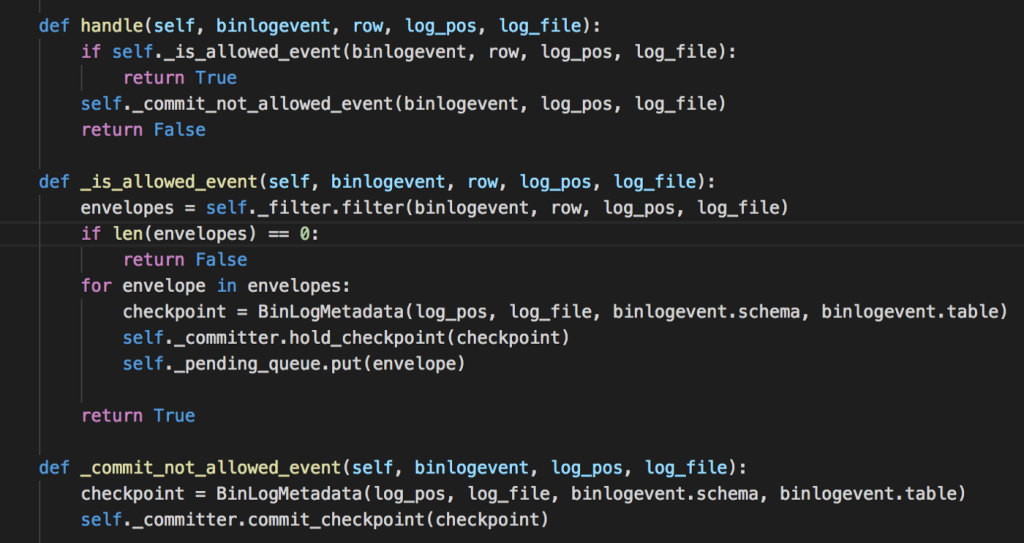
Phần trước tôi đã trình bày về hướng tiếp cận sử dụng mysql binlog để giải quyết vấn đề tích hợp. Trong quá trình triển khai giải pháp nảy sinh các vấn đề sau mà nhóm cần phải giải quyết:
- Quản lý checkpoint: worker có thể tắt đột ngột, nếu khởi động lại làm thế nào để worker biết vị trí offset cuối cùng của file log để quay lại đọc tiếp?
- MySql ghi log tất cả các thay đổi, worker chỉ lọc ra các thay đổi nhất định gửi đi. Làm thế nào để đảm bảo thứ tự commit checkpoint chính xác với thự tự các checkpoint đọc được?
- Làm thế nào để đảm bảo performance của worker. Database tiki có thể ghi nhận tới 10k thay đổi một giây. Tất cả các thay đổi được streamming real time cho worker. Nếu worker không xử lý tốt sẽ dẫn tới độ trễ lớn.
- Các cơ chế retry thế nào để đảm bảo tính chính xác và ổn định tuyệt đối của worker. Một ngày database tiki ghi nhận tầm 50 triệu lần thay đổi. Bất cứ sự rối loạn nào khi xử lý của worker đều có thể dẫn tới sự không ổn định và rất khó để truy vết, khắc phục.
Trong phần này, tôi sẽ trình bày chi tiết quá trình triển khai, có vấn đề và khó khăn mà nhóm phải giải quyết, cũng như các hướng mở rộng về sau.
- Ý tưởng cơ bản về xử lý log.
Log file là một cấu trúc dữ liệu mà các dữ liệu sinh ra chỉ được gắn thêm vào cuối file. Mỗi một dữ liệu log được đặc trưng bởi file vật lý lưu trữ, và vị trí offset của dữ liệu trên file vật lý. Offset là một số nguyên dương từ 0 tới n.
Chương trình đọc log sẽ tuần tự đọc từ một vị trị xác định tới vị trí cuối cùng của một log file. Để biết đã đọc tới vị trí nào, chương trình xử lý log lưu trữ mỗi vị trí đọc được. Nếu bị gián đoạn, chương trình có thể bắt đầu đọc lại từ vị trí cuối cùng được ghi nhận.
2. Yêu cầu của chương trình.
- Chương trình nhận tuần tự từng log do mysql streamming về.
- Mỗi log nhận được sẽ được filter theo điều kiện để gửi vào Kafka.
- Chương trình phải ghi nhận được vị trí của từng log đã nhận được.
- Chương trình đảm bảo việc nhận log và gửi kafka không bị block lẫn nhau.
3. Cơ chế quản lý checkpoint.
Checkpoint là vị trí của một dữ liệu log trong log file. Checkpoint được đặc trưng bởi file lưu trữ và vị trí offset trong file. Mỗi khi đọc được một dữ liệu log, chương trình sẽ lưu trữ lại vị trí đã đọc được. Các checkpoint sẽ được commit vào một file log. Vị trí cuối cùng của log file là vị trí cuối cùng ghi nhận được.
Các vấn đề khó khăn cần xử lý:
- Mỗi một log đọc ra được gửi bất đồng bộ vào Kafka. Chương trình chỉ commit checkpoint của các dữ liệu đã gửi thành công vào kafka.
- Các dữ liệu nhận được, tuỳ điều kiện sẽ được filter gửi vào kafka hoặc không. Nhưng tất cả các dữ liệu log đọc được đều phải được commit checkpoint đúng thứ tự.
Cả hai vấn đề trên có thể phát biểu tổng quát lại là: các log được đọc ra tuần tự, nhưng mỗi log được xử lý độc lập và có thời gian xử lý khác nhau, làm thể nào để đảm bảo các log được đọc ra đúng thứ tự, nhưng sau khi tất cả các log được xử lý hết thì thứ tự commit vẫn phải giống như thứ tự đọc được. Tưởng tượng nó giống như một đoàn người xếp hàng vào siêu thị mua hàng, làm sao để thứ tự người đi vào thế nào thì thứ tự đi ra cũng giống như vậy.
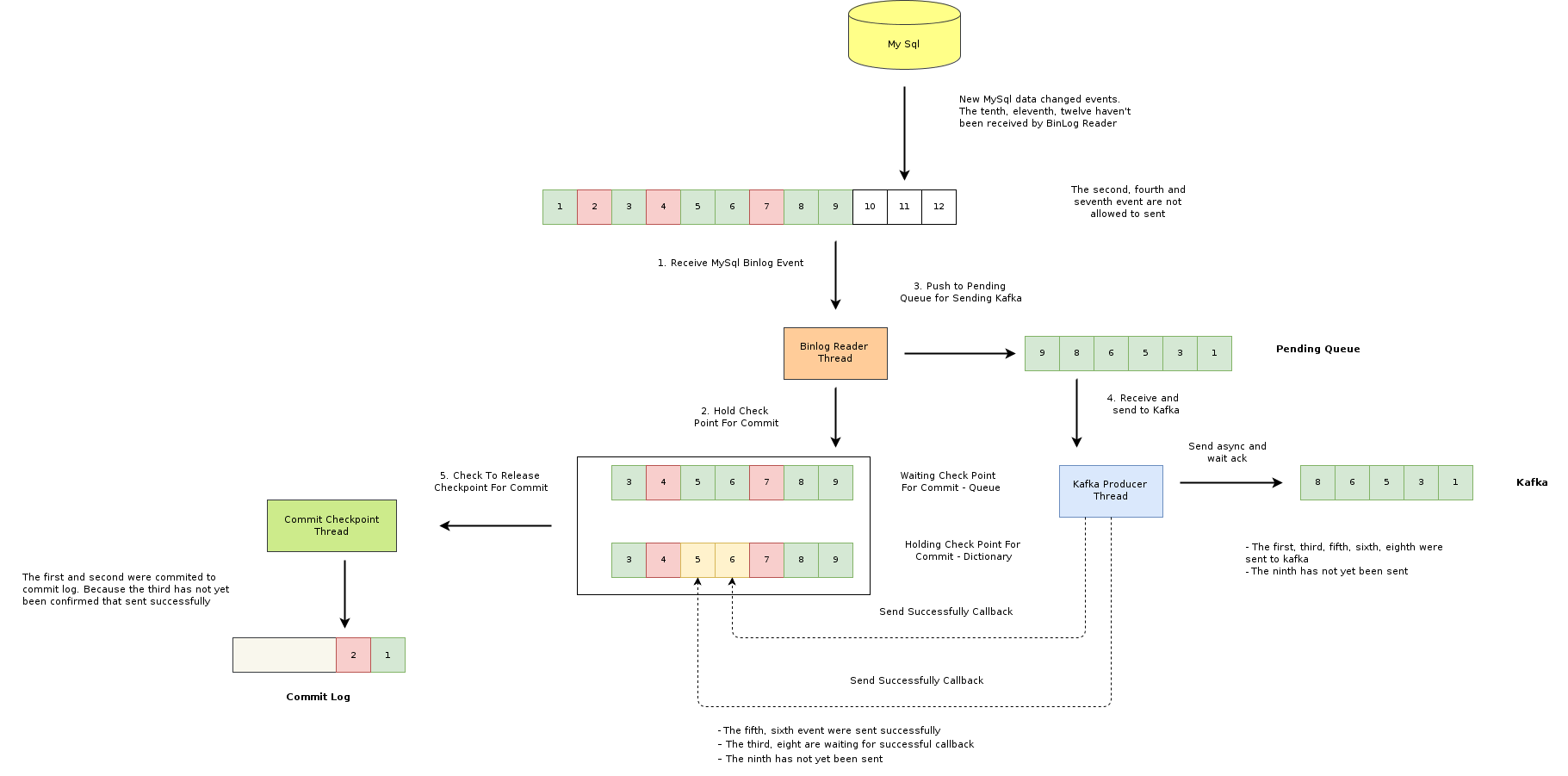
Nguyên lý:
- Mỗi thay đổi dữ liệu của mysql ghi vào binlog được gọi là một event. Trong đó có các event thoả mãn điều kiện được gửi vào kafka (màu xanh) và các event không thảo mãn để gửi đi (màu đỏ).
- Tất cả các event đọc được đều được lưu vào một queue (waiting checkpoint queue) và đánh dấu trạng thái chưa được gửi đi vào một cấu trúc dictionary (holding checkpoints). Một thread bất đồng bộ sẽ kiểm tra các event nhận được để commit vào log file. Quá trình commit sẽ diễn ra tuần tự cho tới khi gặp event bị lock do chưa nhận được xác nhận gửi thành công.
- Tất cả các event thoả mãn điều kiện gửi đi đều được gửi tới Kafka bất đồng bộ. Mỗi event được gửi thành công, sẽ callback bất đồng bộ đánh dấu gửi thành công ở holding checkpoint.
Hiểu đơn giản là đoàn người vào siêu thị nhặt hàng sẽ được một người giám sát thứ tự. Tất cả những người nhặt hàng thành công đều phải xếp hàng ở cửa ra. Chừng nào người giám sát chưa thấy đúng thứ tự đi vào, thì chưa cho những người đã hoàn tất ra trước. Nếu tất cả đúng thứ tự, thì sẽ cho đi ra tới chừng nào thứ tự không còn đảm bảo.
Quá trình gửi Kafka:
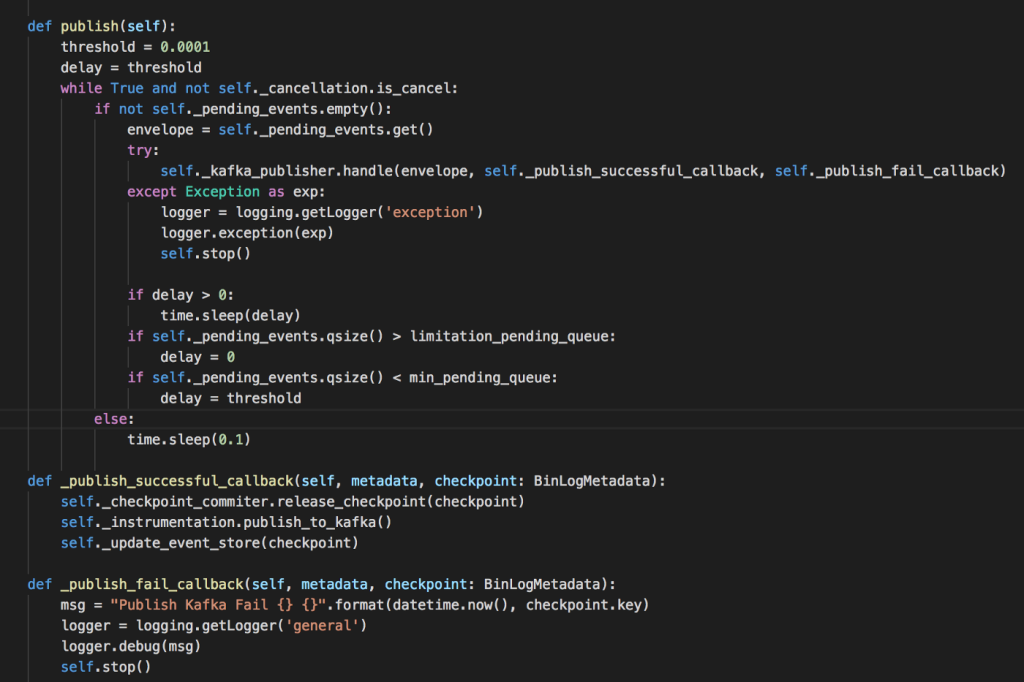
Sau khi nhận callback thành công, commiter sẽ release checkpoint khỏi holding dictionary, để tiến hành commit vào log file. Commiter thread sẽ check các event về trạng thái gửi thành công. Ngay khi checkpoint được release khỏi holding dict, commiter sẽ tiến hành release tất cả các checkpoint đang chờ trong waiting queue.
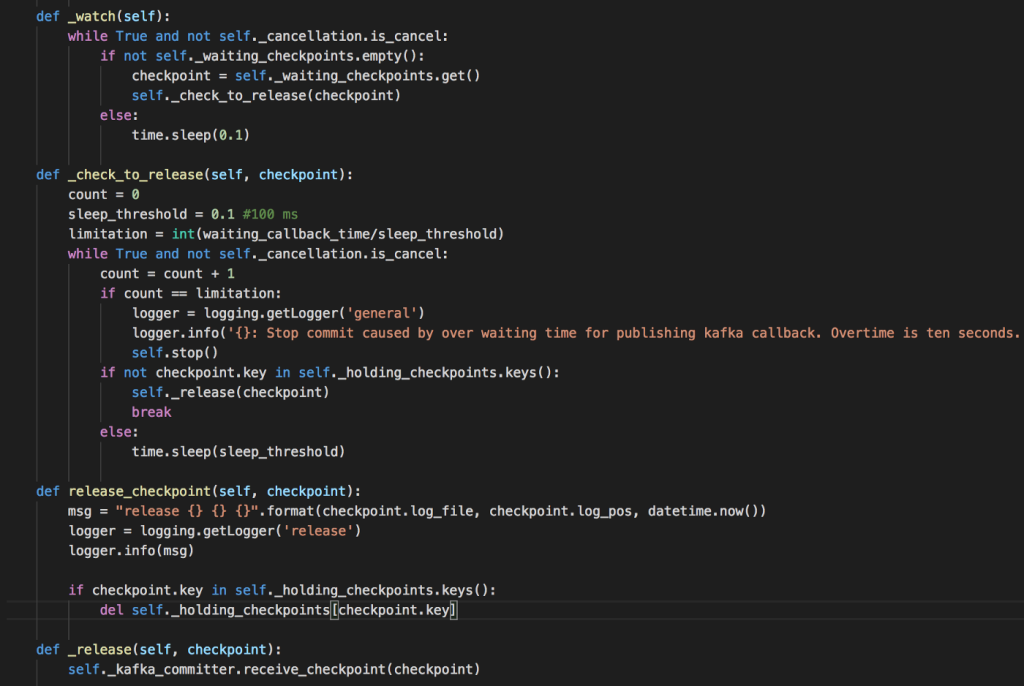
Commit Checkpoint: Các checkpoint khi được release khỏi waiting queue, sẽ được ghi vào log file. Nhưng nảy sinh vấn đề là lượng đọc log rất lớn, có thể tới 10k/seconds, liệu có cần ghi tất cả các checkpoint không? Vì để resume chỉ cần checkpoint được commit cuối cùng. Giải pháp đưa ra là không commit tất cả checkpoint, mà chỉ sau một lượng n checkpoint giải phóng mới commit một lần, và trong khoảng thời gian được cấu hình. Điều này dẫn tới rủi ro nếu ứng dụng bị ngắt khi chưa kịp commit checkpoint cuối cùng nhận được, nhưng nó chỉ gây ra việc đọc lại các log đã gửi mà thôi.
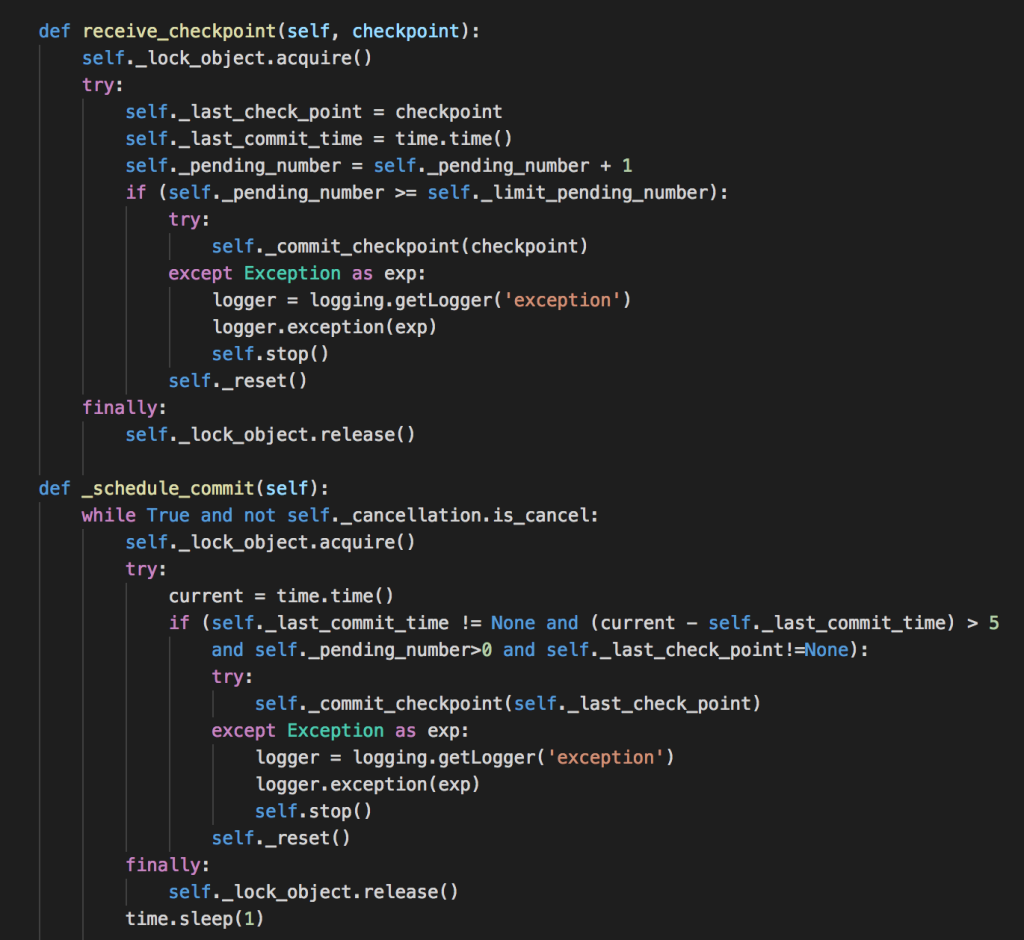
Trong thực tế, worker được cấu hình cứ 1000 checkpoint sẽ commit một lần. Thời gian đợi để commit không vượt qua 5 giây.
Lưu trữ commit log: Commit log lưu trữ tất cả vị trí các checkpoint đọc được. Khi worker bị khởi động lại, sẽ lấy vị trí cuối cùng đã commit để bắt đầu đọc log. Chúng tôi sử dụng chính Kafka là commit log, tất cả các checkpoint sẽ được gửi vào một topic, khi worker khởi động sẽ lấy lastest offset của topic lưu trữ checkpoint.
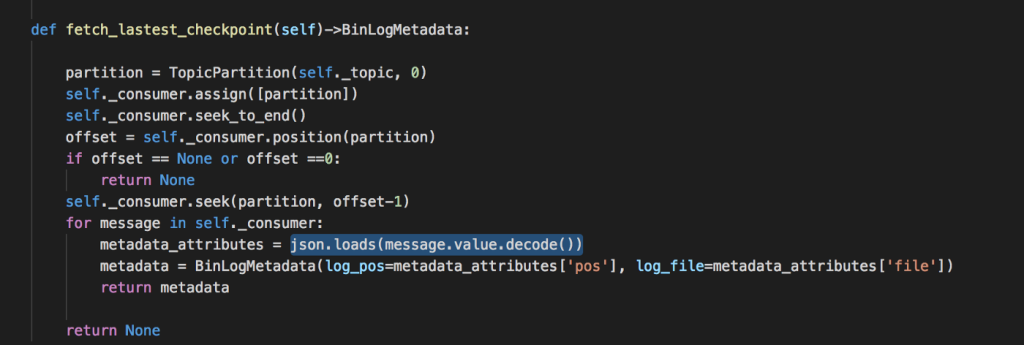
4. Đảm bảo bảo thứ tự message khi gửi vào kafka.
Trong phần trên chúng ta thấy một vấn đề: điều gì sẽ xảy ra nếu một event gửi đi và không nhận được callback trở lại. Khi đó toàn bộ waiting checkpoint sẽ không được giải phóng. Để xử lý vấn đề này commiter thread có cấu hình thời gian timeout đợi callback, nếu vượt quá sẽ tiến hành reset lại toàn bộ quá trình.
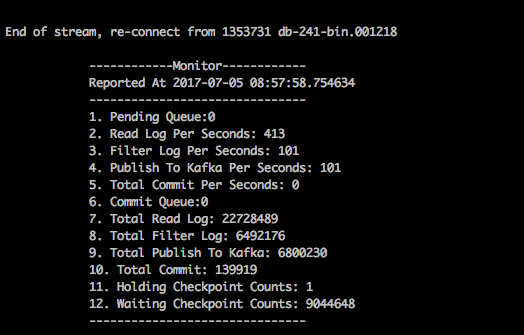
Như trong hình trên, hơn 9 triệu event đã bị ùn lại chỉ vì một event không nhận được callback.
Trong quá trình phân tích, nhóm cũng rút ra được các mode cấu hình quan trọng của Kafka. Thật thú vị khi biết rằng Kafka hoàn toàn có thể để mất message hoặc sai thứ tự. Đó là bởi Kafka được cấu hình mặc định để ưu tiên performance khi produce các message.
Cơ chế nhận ACK: Khi gửi message tới Kafka, thì có ba chế độ: không nhận ack, nhận ack từ leader node, nhận ack từ tất cả các node replica. Để đảm bảo tuyệt đối không mất data, cần cấu hình chọn chế độ ack từ tất cả các node replica.
Số lượng request mỗi connection: Ở cấu hình mặc định, Kafka Producer thiệt lập 5 request cho mỗi connection. Điều này sẽ có thể gây ra sai thứ tự nếu khi producer retry nếu một leader node bị lỗi. Để đảm bảo thì cần thiết lập số request cho mỗi connection là 1.
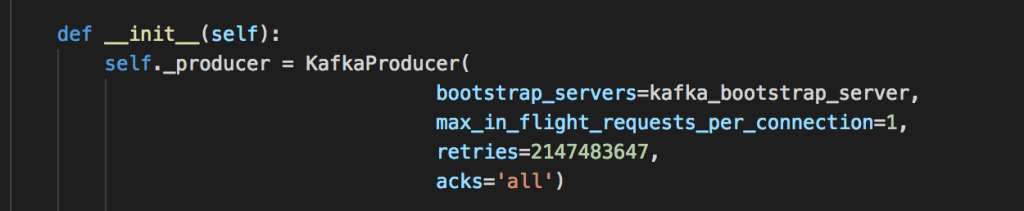
5. Để đảm bảo hiệu năng.
Để đảm bảo throughput của chương trình, worker sử dụng các queue để giao tiếp giữa các thread. Mục tiêu giảm thiểu tranh chấp tối đa giữa các thread.

Khi đọc binlog không filter, worker đạt tới 10k message/seconds. Trong chế độ vừa đọc vừa gửi, worker có thể tới đạt 4.5k message/seconds vào ra.
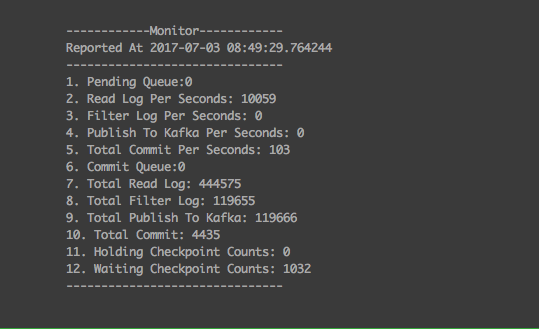
Trong luồng thực thi trên, thì hai thread đọc log và gửi kafka là hai thread hoạt động chính.
6. Cơ chế xử lý exception lỗi.
Có ba tiến trình chính: đọc log, gửi kafka và commit checkpoint. Độ ổn định của toàn bộ chương trình quyết định bởi hoạt động của từng thread. Các tình huống xảy ra:
- Nếu tiến trình đọc log bị gián đoạn: dẫn tới việc không thể nhận log, do đó các thay đổi trong mysql không thể gửi đi và làm toàn bộ quá trình tích hợp bị dừng lại.
- Nếu tiến trình gửi kafka bị lỗi: các message sẽ không được gửi đi, log đọc được sẽ bị tồn lớn và dẫn tới tràn bộ nhớ.
- Nếu tiến trình commit bị lỗi: các checkpoint có thể không được commit đúng thứ tự, hoặc bị mất checkpoint, dẫn tới nguy cơ bị lost message khi worker khởi động lại.
Do đó bất kì một khâu nào trong các khâu trên gặp vấn đề đều dẫn tới nguy cơ sai lệch và khó khắc phục, tra cứu. Vì vậy bất kỳ một khâu nào bị lỗi thì sau n lần retry, nếu không được thì đều phải khởi động lại toàn bộ quy trình. Việc này được thực thi được nhờ các thread đều chia sẻ một đối tượng cancellation, cho phép một tiến trình bất kỳ có thể stop tất cả các tiến trình khác, khởi động lại toàn bộ chương trình và đưa ra cảnh báo. Nó giống như một nút dừng khẩn cấp trên một cái băng truyền trong nhà máy.
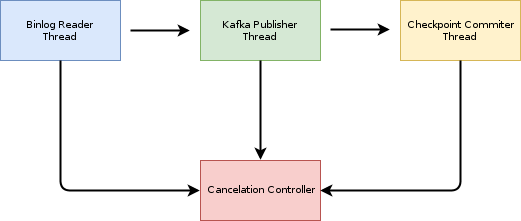
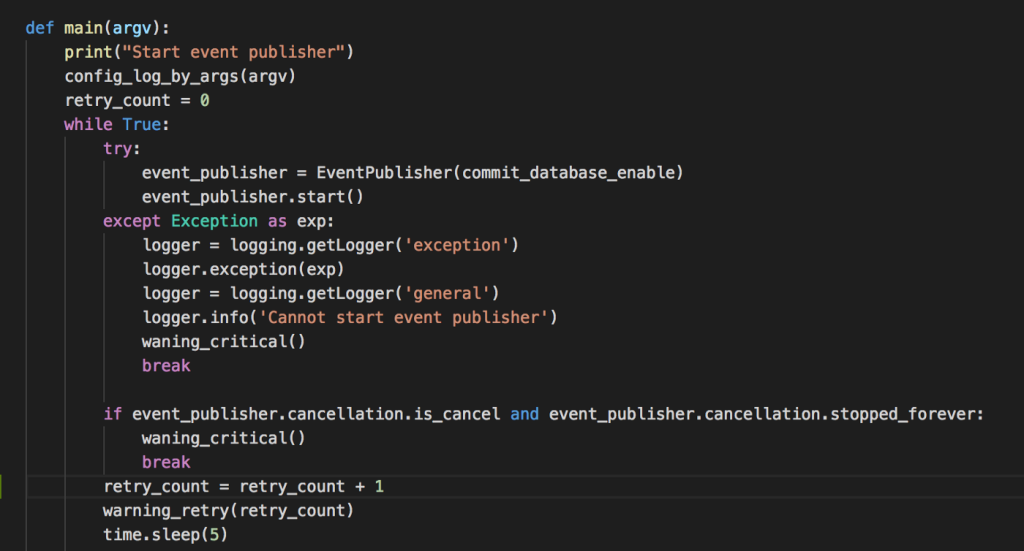
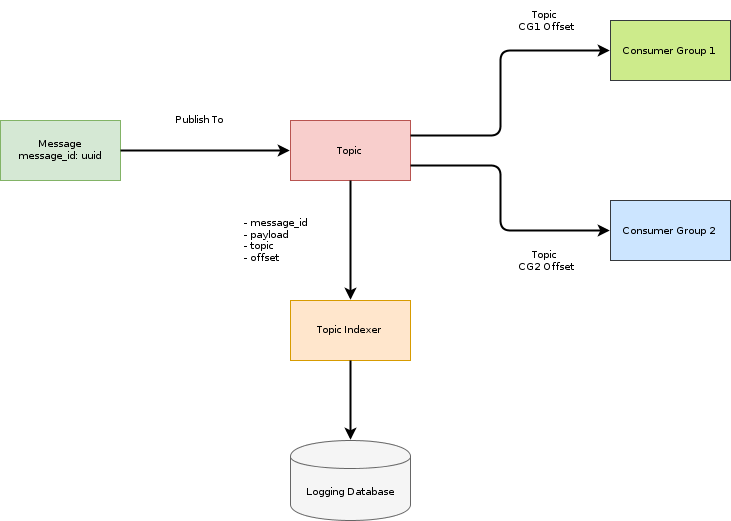
7. Cơ chế tracing message.
Tất cả các message được định danh bằng mã UUID v4. Các message được xác định trên kafka bởi topic,offset. Tất cả các message gửi đến kafka thành công đều được index lại trong một hệ thống log tập trung để tra cứu. Mỗi một topic được consume bởi nhiều consumer group. Mỗi consumer group có thể theo dõi trạng thái qua định danh group và offset mỗi group consume được. Dựa trên model đó, quá trình tracing message có thể thực hiện như sau:
- Dựa trên mã định danh UUID và hệ thống log có thể xác định được message đã được gửi hay chưa
- So sánh offset của message và offset của từng consumer group có thể xác định một message đã được một consumer group nhận được hay chưa.
Kết luận:
Trên đây tôi đã trình bày lại toàn bộ quá trình triển khai giải pháp tích hợp sử dụng mysql binlog. Tích hợp là một nhu cầu cấp thiết đối với không chỉ riêng tiki mà nói chung với tất cả các hệ thống lớn. Qua quá trình triển khai chúng tôi thu được các bài học kinh nghiệm sau:
- Dữ liệu cần phải tuyệt đối chính xác. Trong môi trường phân tán, mọi sự cố về network, server, application đều có thể gây ra sai lệch. Việc đảm bảo transaction giữa hai data source khác nhau là không thể. Do đó cần phải xây dựng model tích hợp sao cho dữ liệu thay đổi đi theo một chiều duy nhất.
- Xử lý bất đồng bộ là bắt buộc trong tích hợp. Việc phân tích các các trường hợp đúng (happy path) và các trường hợp ngoại lệ (exception path) có vai trò quyết định với việc đảm bảo độ ổn định.
- Để đảm bảo performance cần phải đảm bảo khả năng xử lý không bị tranh chấp. Thực tế triển khai, chỉ cần thread bị lock gián đoạn 1/1000 giây, có thể làm giảm throughput từ vài ngàn message/giây xuống còn vài trăm message/giây.
- Các hệ thống cảnh báo, monitor có vai trò vô cùng quan trọng. Cần phải xây dựng nó cẩn thận như là một phần quan trọng của kiến trúc.
Bạn cho mình hỏi là Worker bạn dùng Python để đọc binlog của mysql ạ?
Cảm ơn bạn đã chia sẻ 😀 Bên bạn deploy trên K8S không hay mô hình deploy bên bạn như nào ạ