1. Introduction.
For a long time, handling inventory had been such a pain point for our TIKI system. We couldn’t serve the massive traffic in the peak sales event and prevent to sell over the limited quantity of flash deals. Each event like Giựt Cô Hồn, legendary sale seasons, is a nightmare with us. We had to build a separate website or do many tricks to serve our customers. But the result was not encouraged. Customer’s orders were canceled because the system sold over its inventory, or lost the game without understanding why. All of these problems came from inventory processing. Our system couldn’t guarantee the consistency of data at the peak sales event. We had only two options: consistency of data but overloaded at peak time, or inconsistency but alive — a really bad option and a bad option. Of course, we had to choose the second option. We accepted to sell over the quantity of some hot products sometimes and had to cancel orders and compensated coupons for customers. But It was really suffering, stressful, and exhausted. At each peak time, our business team had to watch the performance report to turn off hot SKUs manually. But time over time, our business grew faster and faster. It grew too rabbit. We couldn’t accept bad customer experiences like that anymore. In June/2018, the challenge was pushed in our roadmap, we had to rebuild the catalog platform to scale and adapt to our business. But we only could start the project in June/2019 when we understood the problems, technology thoroughly and gathered enough the best engineers. We released at the end of September/2019, right before 10.10.2019. Since that time, our system proves the reliability and scalability to serve business growth.
2. Inventory Problems.
Inventory is crucial for an eCommerce system. Every transaction is based on the price and quantity of a product. The reliability of the system relies on the inventory so much. To scale the business, the system has to handle many critical problems of inventory. There are two critical problems:
- The consistency data of inventory: The data of inventory is required high consistency. The system doesn’t allow to sell over the quantify of a product. There are millions of products and each product has stock at many locations of many warehouses. The number quantity of each warehouse is accumulated to the inventory of a product on the eCommerce website. The data of inventory are updated frequently by customers and warehouse operations. So It is very complex to guarantee the consistency of data. It is much harder when the system has to scale to handle the high volume of traffic. At peak times, thousand of customers race to place orders of very cheap products. How to scale but guarantee the consistency of data is the most challenging problem of the inventory system.
- The complexity of integration with other systems. The number quantify of a product is very important for all operations. So the inventory system has to integrate with other systems, especially with checkout and warehouse systems deeply. The data flow is long, comes from the warehouse, through checkout, order, and delivery. If the data is missing at any step, it can break the system, and hard to trace the inconsistency.
3. Approaches.
Dealing with the consistency inventory’s data to scale is the challenge to design the system. To tackle these problems, these approaches are:
- Using the local memory and non-blocking processing to handle the scalable problems. I/O bottleneck is the main problem to scale the system. The inventory data is stored in local memory and is processed by applying the non-blocking model to maximize the power of the CPU.
- Using a single command queue and a single master model. It is tough to deal with consistency problems in a distributed system if the system allows different update data flows. By using a single data flow, it is easy to maintain the consistency of data and recover as well.
- Proactive to maintain consistency of data when integrating with external systems. When a customer places an order, its transaction is spanned many systems: checkout, inventory, payment… So the consistency of the inventory data is not only dependent on the inventory itself, but also on external systems like the checkout system. If the inventory data is updated but the order is failed, the inventory system has to reverse to maintain the consistency of its data.
- Using one update data flow to integrate with warehouse systems. The inventory data is updated by both sides: customer and warehouse. As usual, there are two data flows: one for customers and one for the warehouse, the data is synced from the warehouse systems, and then updated for customers to operate. But it is harder to maintain consistency of data if there are many data flows. The inventory system treats the update from the warehouse as the same as the update from customers. It uses a unified command queue to maintain all updates of the inventory data.
4. Architecture.
The most challenging is to handle the consistency of the inventory’s data. The inventory’s data requires high consistency. The system doesn’t allow to sell more than the quantity of each SKU. The straightforward way is to use a locking mechanism. But in this way, it causes bad performance and can’t scale to handle a large volume of traffic, especially at peak time when thousands of customers are racing to place orders. To solve this problem, the architecture has to satisfy two critical things:
- Guarantee the eventual consistency of the inventory data. There are many kinds of data sources, like MySQL, Kafka, local memory. These data sources have different characteristics. MySQL is good at persistence and consistency but is not good at performance when has to handle the locking; the local memory is good at performance but is not durable… But by combining the characteristics of each data source, the system can handle the scaling problem. But if the inventory data is stored in different data sources, all these data sources have to be eventually consistent even when the system is crashed suddenly, otherwise, the system is not reliable to handle the inventory transactions.
- Using a Single thread-based model and local memory but must handle a large volume of traffic. If the system can guarantee the eventual consistency of the inventory data of many data sources, it allows applying advanced techniques to handle the transaction. The approach here is to store data in local memory and use non-blocking techniques to maximize the throughput.
4.1. Consistency Model.
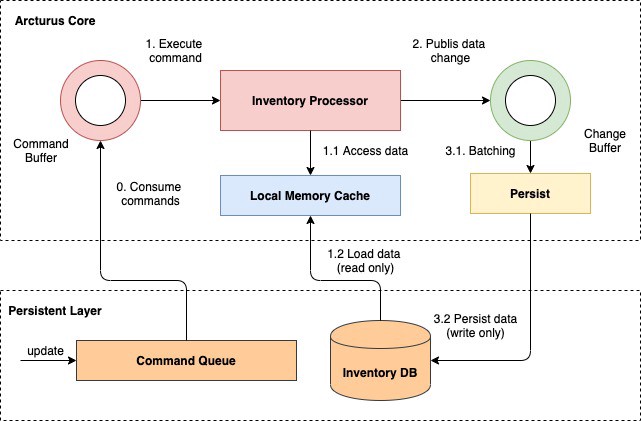
To deal with the eventual consistency problems, the design is based on the transaction log model. The state of the system is not only the state of data in the database but also the state of each command to update the inventory’s data. So the state of the system has been changed since it received the update command from external systems (checkout, warehouse, order management system…). Each state change of the system is stored in a command queue with a specific offset. The offset of the state is used as the checkpoint to recover the state of the system anytime. It is the main idea to guarantee the eventual consistency of the data.
The system has one command queue. If an external system wants to update the inventory’s data, it will send a command to the inventory system. The command is stored in a command queue. The command queue is used as a transaction log to maintain the state of the system. There are two main data sources that need to be eventually consistent: the command queue and the persistent database. The offset of the persistent database is always less than or equal to the latest offset of the command queue.
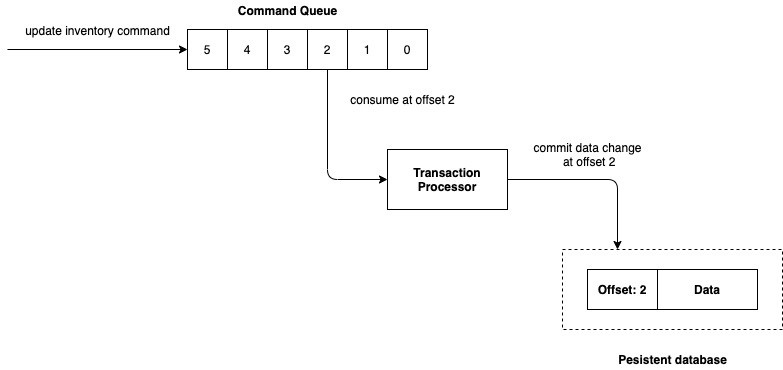
The algorithm to maintain the eventual consistency is:
- Step 0: The processor loads the data with the latest offset from the database and starts consuming the commands
- Step 1: If the offset of the database is less than the lastest offset of the transaction processor, it starts consuming and applying changes from the offset of the database until it reaches the latest offset of the command queue, and continue to process the next commands on the future when they come.
- Step 2: If the offset of the database is greater than the lastest offset of the transaction processor, it starts consuming from the lastest offset, apply changes to data in memory, but doesn’t persist these data changes until it reaches the offset of the database.
By applying this model, the system solves the eventual consistency problem properly. It guarantees the eventual consistency between all data sources. This mechanism is the backbone to scale the system later, it opens many solutions to handle high concurrency requests and keep the reliabilities of the whole system. People usually say: “There are only two hard things in Computer Science: cache invalidation and naming things.”. But with this model, the system is reliable to replicate data between many data sources: command queue, local memory, database, and server nodes.
4.2. Processing Model.
The system has to handle a thousand transactions per second when customers race to place orders. Many customers can buy one SKU and one customer can buy many SKU at the same time. The system has to solve two hard problems: high throughput but guarantee the consistency of data. These problems require different optimization strategies and these strategies usually conflict with each other. If the system wants to maximize the throughput, it will cause the race condition to update data, and to guarantee the consistency of data, it will block the processing of the other.
The common approach is to optimize the CPU to handle multiple tasks at the same time. But actually, the CPU is not good at performance when It has to handle multiple tasks at the same time. The CPU has to switch the context to handle separated tasks, whenever It switches the context, it slows down the processing. It is worse when the system has to handle more customers at peak times. More than that, the system has to guarantee the consistency of inventory data. If many customers race to place an SKU, there will be many threads that are trying to update the inventory data. If the CPU serves one thread, it has to block the other threads and switches to the other threads after finishing. It will cause more context switching and decrease performance and throughput so much. To maximize the power of the CPU, the system has to decrease the context switching. There are two approaches to tackle this problem: reducing the number of concurrent threads and store the data as nearer to the CPU as possible.
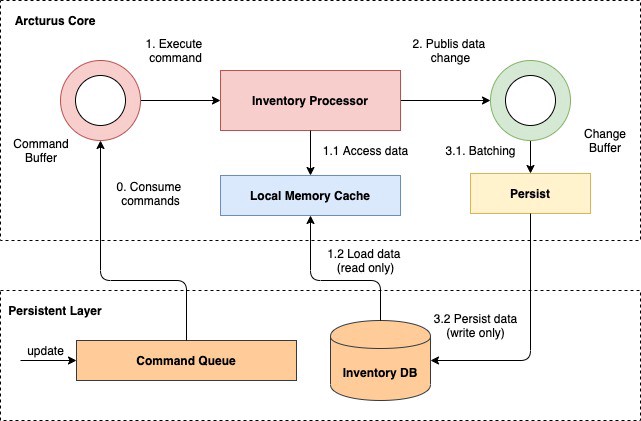
All the inventory data is stored in the local memory. It is loaded from the database if it is not available in the local memory. All data changes are published to another queue to persist in batches asynchronously. By applying the above consistency model, the system can guarantee the eventual consistency between the command queue, local memory, and the database. The data flow is one way, loading data, processing, and writing data are separated in different flows. Based on the offset of the data, the system can manage the consistency easily. It can decide to consume commands to replay the state of the data in memory or skip. Because of one-way data flow, it also removes the lock at the database and optimizes the I/O bottleneck much.
When the data is ready and available in the local memory, the CPU can access the data quickly and easily. How to optimize the performance of the CPU is a challenge. Instead of dealing with the multiple threading problem, the system is designed to use a single thread to process transactions. It is the best way to deal with high concurrency requests. It reduces the context switching and maximizes the throughput of processing. There is a queue to buffer commands to process sequentially. The system uses a special non-blocking queue: ring buffer. It is based on a famous open-source: Disruptor L-Max. It can handle up to 1 million transactions per second. There are two rings: one for buffering commands to process and one for buffering the data changes to persist in the database asynchronously.
4.3. Checkout Integration.
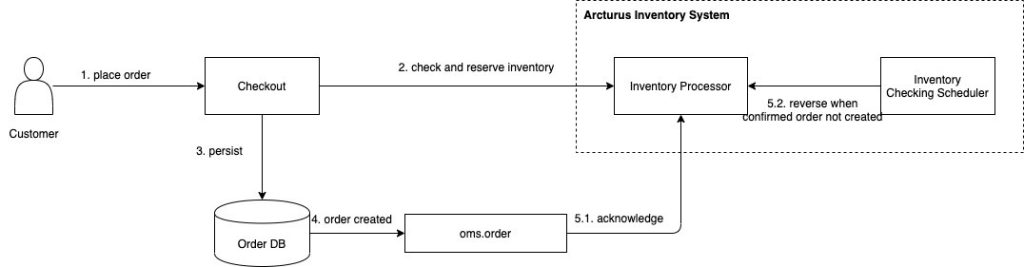
The consistency data of order and inventory are crucial. It requires the integrity and consistency of the number of sold items with the quantity of each SKU. When a customer places an order, systems have to update a lot of data. There are two important data: order and inventory. These data are managed by two separate systems: checkout and inventory. These systems expose HTTP API for integration. Because of the property of HTTP, the system can’t create an atomic transaction to update the order and inventory data of two systems. So there is a risk for the inconsistency of order and inventory data: the inventory’s data is updated for a new order, but the order can’t be created successfully, then the inventory of an SKU is lost and can’t be used for the next customers. To solve this problem, the processing is separated into two phases:
- Reserve the inventory. When an order is placed, the checkout system makes a request to the inventory system to reserver the inventory of an SKU. The quantity of an SKU is reserved temporarily.
- Receive the order event to confirm the quantity or reverse the quantity and make its inventory to be available for new customers.
4.4. Warehouse Integration.
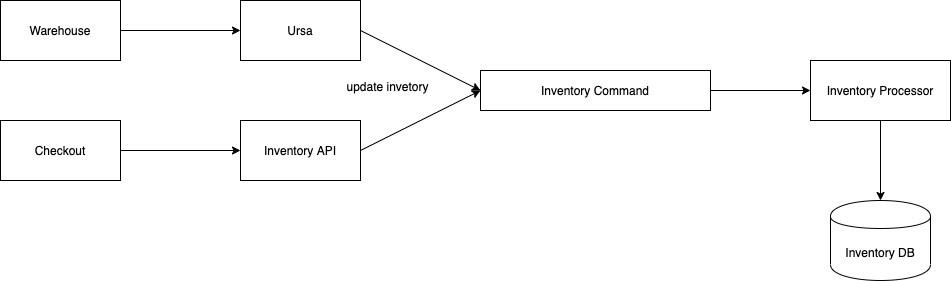
The inventory is updated by both consumers and the warehouse system. The inventory data come from the warehouse system and will be subtracted by the customers when they place orders. At the warehouse system, the operation is very complex, the product is in or out of the warehouse very frequently. The data flow from warehouses is crucial for all operations of TIKI’s eCommerce platform. It maintains the accuracy of the inventory of each product. We had approached by separating this flow from the consumer flow. It is very normal thinking, one system for streaming data from the warehouse, one system for consumers to update inventory. We had spent a few months before completing this module, named this module Ursa. Actually, Its logic is much complex than the logic of consumers. After finishing Ursa, we started the Arcturus and realized that by separating into two systems, we have to maintain the duplicated logic of the quantity of the product. Especially, It is very hard to maintain the consistency of data. The inventory data is updated by two different flows, but its data is stored in two data sources: in-memory and the persistent layer — MySQL. Rather than trying to fix the drawback of this architecture, we stick to the beginning approach by using a single command queue to maintain the update command. We treat all sources of changes equally, no matter from warehouses or from consumers. In this way, we apply one model consistently. It is much easier to maintain the logic and consistency of data.
4.5. Overall Architecture.
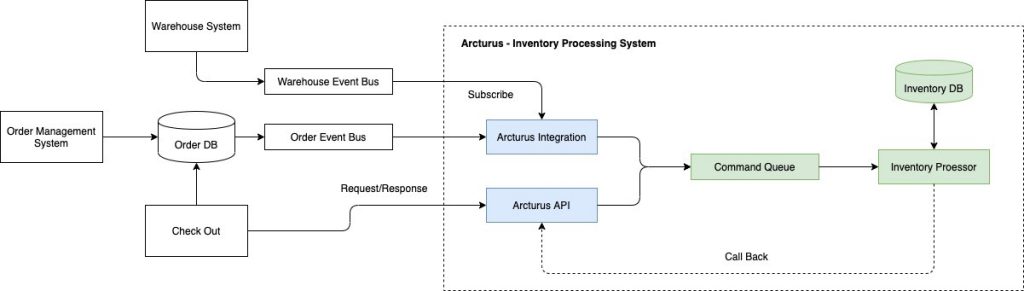
The system is built based on:
- Java 11
- MySQL — Database
- Kafka — Message Queue
- Guava — Local cache
- L-Max Disruptor — Ring Buffer
- Gridgo — Non-Blocking I/O framework
- ZeroMQ — for a quick response the command result
- Atomik — Internal Lib based on Disruptor for handling in-memory transactions.
4.6. Benchmark.
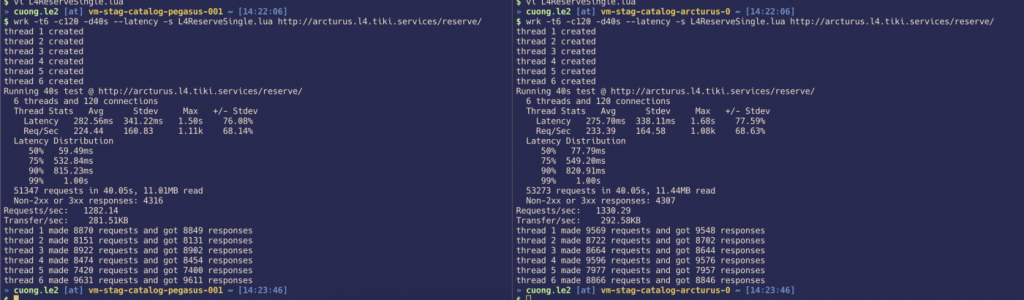
With only processing transaction in memory, don’t care database, the inventory processor can process with rate 350k transaction / s with multi-operator on 1 key.

And testing with full IO (input request from ZeroMQ, output to MySQL), the inventory processor can handle 120k transaction / s (not capture picture, so do not anything to show!)
Throughput
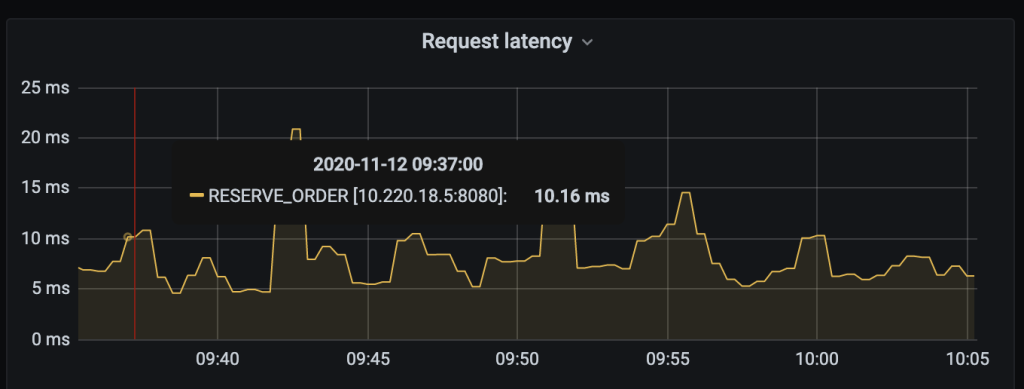
On the Staging, we can handle up to 5600 requests/ seconds:
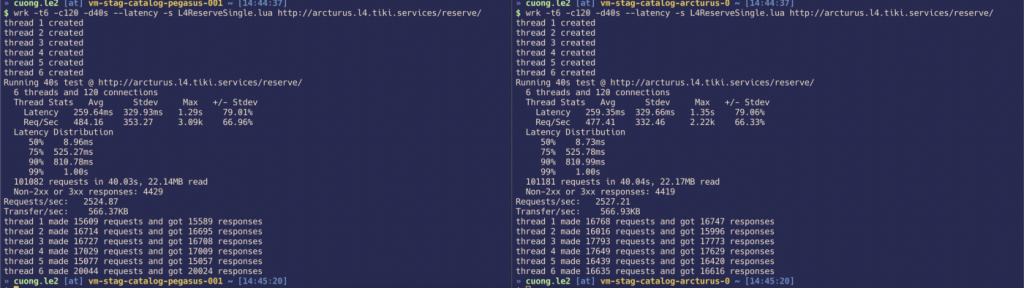
Latency
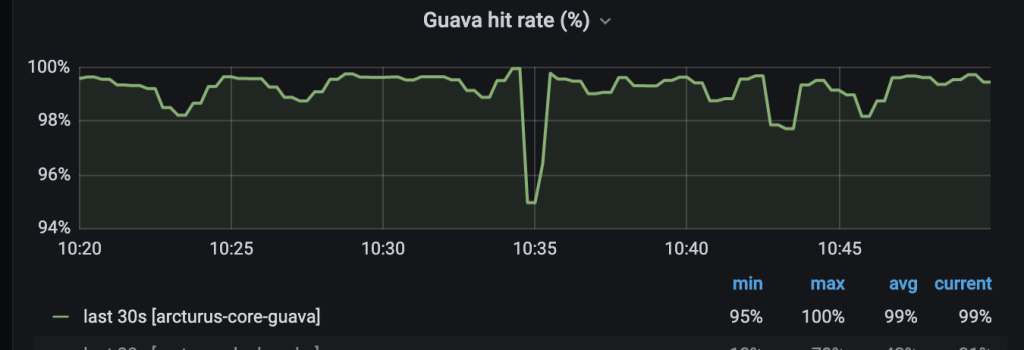
Cache Hit.
AVG cache hit: 99%
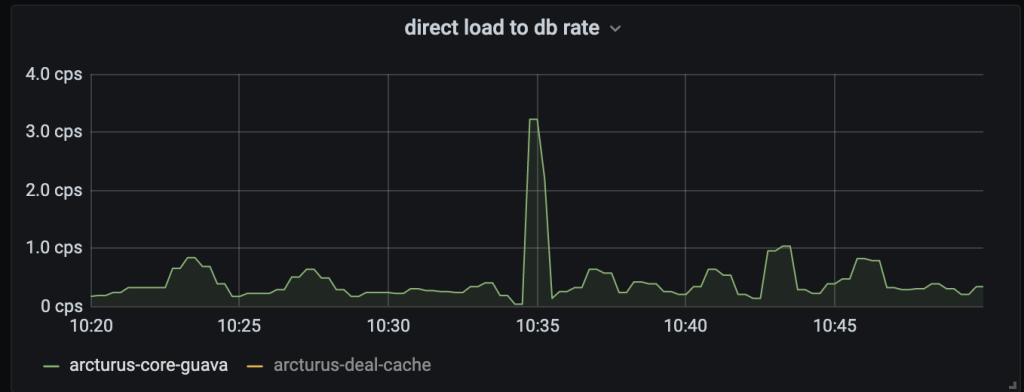
Load database rate: 0.3 requests per second
5. Conclusion.
To build a product, we have to solve many problems systematically. The most challenge of this project is to combine many approaches and solutions into one plan to solve once time. We were not reactive to tackle problems one by one. Because the reliability of the system relies on each problem. There are two very important strategies to build this project successfully:
- Guarantee the consistency of data. The design sticks to this principle very strictly. Data is like a flow, if there is one leaking point, it will break the flow. The system has to guarantee the data flow since the coming of requests until storing successfully.
- Optimize the power of the CPU as much as possible. Ring buffer, non-blocking processing, local caching are centralized of the design. It reduces the context switching, removing the locking, bringing the data near to processing to get the highest throughput of the CPU.
6. Contributors.
Arcturus is one of the most important projects of TIKI. It is complex, hard and so sensitive. Fortunately, TIKI has the right ones at the right time. It was built by the best ones of TIKI and got much support from the whole company to complete and release under the high pressure of the business. The main contributors are:
- Trần Nguyên Bản — Principal Engineer
- Bùi Anh Dũng — Principal Engineer
- Nguyễn Hoàng Bách — Senior Principal Engineer
- Lê Mạnh Cường — Senior Engineer
- Nguyễn Thị Yến Linh — Specialist QC