Chắc hẳn không ít các bạn rơi vào cảnh “Tính năng mới vừa release chạy cực kì tốt” nhưng vài ngày sau lại chạy ì ạch. Hoặc vui hơn là đang hí hửng báo cáo sếp về performance và availability thì… ĐÙNG, hệ thống lăn ra chết chỉ sau một lần gửi notification :D.
Các tình huống trớ trêu trên là không tránh khỏi, nhất là các hệ thống có lượng truy cập cao và thường có sự đột biến về lượng truy cập. Tuy nhiên, không hẳn là không có giải pháp, và một trong những cách thức đó là benchmark hệ thống hiện tại, tính toán và điều chỉnh cho phù hợp và sẵn sàng đáp ứng lượng truy cập mong muốn.
Để đạt được mục đích này, chúng ta cần có một công cụ, và hơn thế là một cơ chế để đánh giá hệ thống.
Cơ chế chúng ta cần là gì?
Việc benchmark một hệ thống thường được hiểu đơn thuần là tạo một lượng lớn yêu cầu (request) vào hệ thống và ghi nhận khả năng đáp ứng (response) tối đa mà hệ thống có thể chịu được, hành động này thường được gọi là stress test.
Tuy nhiên, ứng dụng và các thành phần liên quan (MongoDB, MySQL, ElasticSearch,…) đều có cơ chế caching riêng và thường theo hướng “hot-items” hoặc “most recent items”.
Lấy một ví dụ với một service của Tiki, liệt kê danh sách các việc mà ứng dụng phải làm đáp ứng yêu cầu Liệt kê sản phẩm của danh mục có id là 839, chúng ta có danh sách sau:
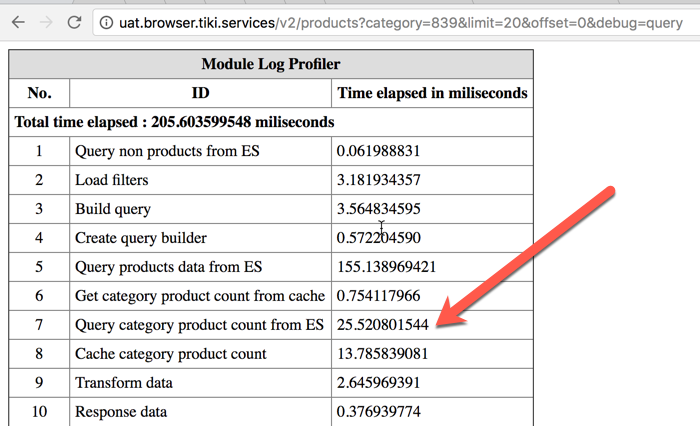
Chú ý vào mục số 7, ngắn gọn là ứng dụng phải truy vấn thông tin danh sách các category con của danh mục 839 kèm với số lượng product của chúng. Sau đó, cache nó lại vào RAM (mục 8).
Thử request lần thứ hai, chúng ta có danh sách sau:
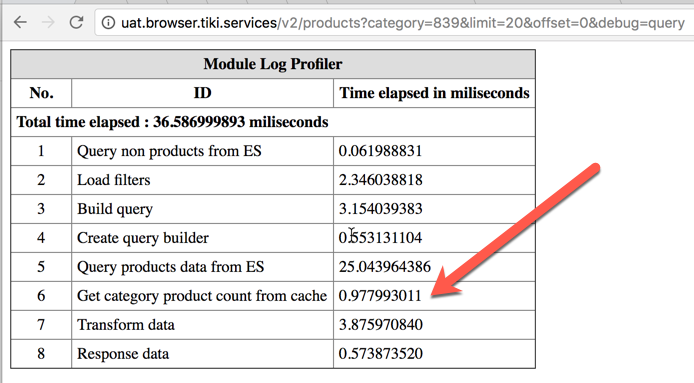
Có thể thấy lần này ứng dụng không cần phải truy vấn thông tin danh mục con kèm số lượng sản phẩm từ ElasticSearch nữa vì đã có trên RAM. Đồng nghĩa với việc này là transaction time giảm, giả sử CPU, I/O load giảm và chúng ta sẽ handle được thêm nhiều request.
NHƯNG, điều này không đúng với thực tế — hành vi người dùng với ứng dụng. Khách hàng muốn nhiều hơn là việc được hiển thị sản phẩm của danh mục, họ còn muốn tìm kiếm, lọc sản phẩm, sắp xếp sản phẩm,…
Một ngày service handle việc tìm kiếm của Tiki có ~ 2,880,000 requests (2k rpm), và có đến 90% requests là uniquehttps://cdn.embedly.com/widgets/media.html?src=https%3A%2F%2Fwww.youtube.com%2Fembed%2FHeWfkPeDQbY%3Ffeature%3Doembed&url=http%3A%2F%2Fwww.youtube.com%2Fwatch%3Fv%3DHeWfkPeDQbY&image=https%3A%2F%2Fi.ytimg.com%2Fvi%2FHeWfkPeDQbY%2Fhqdefault.jpg&key=a19fcc184b9711e1b4764040d3dc5c07&type=text%2Fhtml&schema=youtube
Do đó, việc giả lặp đúng hành vi người dùng khi benchmark là cực kì quan trọng để tránh sai sót.
Điều chúng ta cần đó là một cách thức để capture lại tất cả hành vi hoặc đơn giản là tất cả lịch sử truy cập (request) của người dùng trong một khoảng thời gian, và dùng danh sách này để stress test vào hệ thống.
Cách thức thực hiện thế nào?
Tóm lại, để thực hiện được việc benchmark hệ thống, thì chúng ta cần thực hiện 2 bước sau:
- Capture lại danh sách request của người dùng trong một thời gian
- Sử dụng danh sách này để stress test vào hệ thống
Công cụ
Dựa vào trên, chúng ta sẽ sử dụng các công cụ sau:
Tiki centralize log ở các hệ thống bằng Graylog. Graylog hỗ trợ tốt việc lọc, giới hạn theo thời gian và hỗ trợ export ra CSV.
Công cụ hỗ trợ load test viết bằng Go. Không giống như những công cụ nổi tiếng khác như Apache JMeter, Apache Bench (ab), Siege, hoặc cloud-based Loader.io. Vegeta cho phép chúng ta load test hệ thống tới nhiều target endpoint cùng lúc, cũng như hỗ trợ xuất ra các report với nhiều định dạng và có thể đọc được bởi các hệ thống đồ thị như DyGraph.
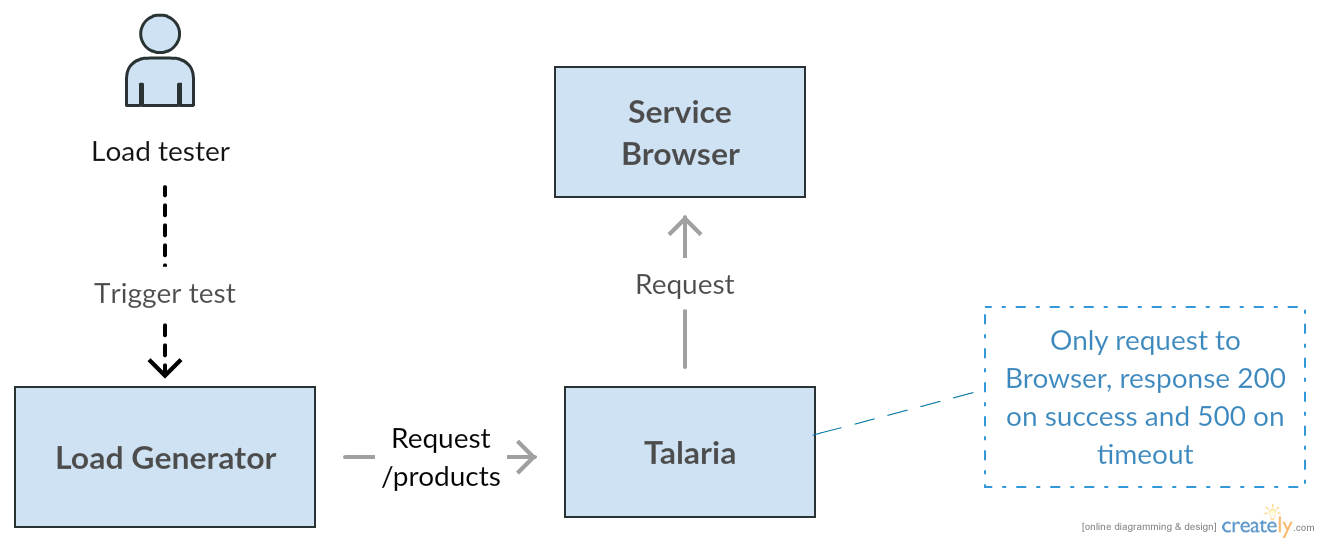
Hệ thống
Việc load test nên được thực hiện trên một hệ thống gần giống môi trường PROD.
Công cụ đóng vai trò tạo load vào hệ thống nên được đặt trên một server riêng nhưng cùng datacenter với hệ thống cần load test. Việc làm này nhằm đảm bảo một điều kiện lý tưởng để đạt được mức CCU (concurrent users — lượng người truy cập đồng thời) mong muốn.
Mô hình team Discovery của Tiki đã dùng để load test trước đây.
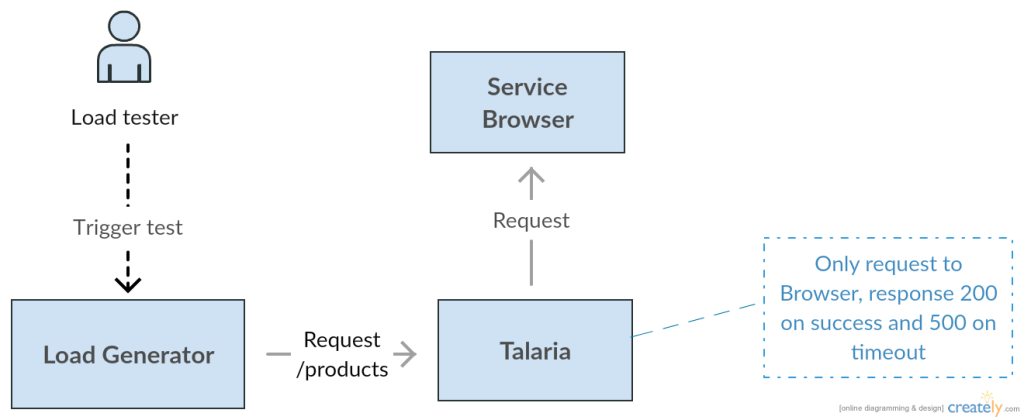
Như mô hình trên thì Load Generator và Talaria sẽ nằm ở hai server khác nhau, tuy nhiên 2 server này đều nằm chung trên VDC.
Thực hiện
1. Lấy danh sách request của người dùng
Graylog đã hỗ trợ mọi thứ đúng với nhu cầu của chúng ta trong bài viết này, việc này có thể thực hiện đơn giản như sau:
Định dạng danh sách request mà Vegeta yêu cầu như sau:
GET http://goku:9090/path/to/dragon?item=balls
GET http://user:password@goku:9090/path/to
HEAD http://goku:9090/path/to/success
Do đã thống nhất chỉ load test với READ request (GET method), nên chúng ta chỉ cần thực hiện một thao tác “tin học văn phòng” nhỏ để có được danh sách như format trên. Ví dụ như file dưới đây: http://bit.ly/2upDcwP.
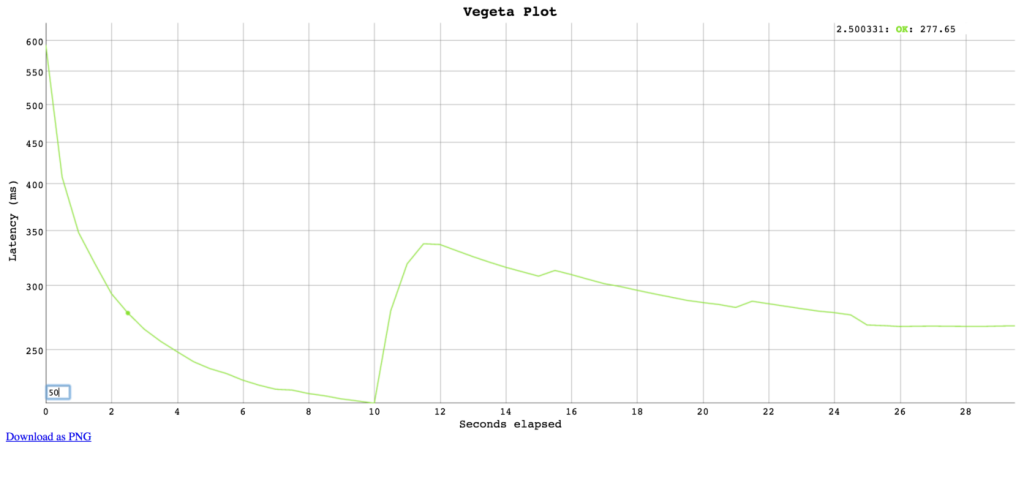
2. Cài đặt và load test bằng Vegeta
Let’s rock and roll

Audit report — Chúng ta quan tâm gì?
Một phần quan trọng khác chính là audit report chúng ta có được sau khi benchmark. Report này bao gồm:
- CCU đạt được
- Response time (by Average và Percentile) (mostly from load tool)
- Sức khỏe hệ thống: CPU, Memory, I/O,…. (từ NewRelic)
Trước khi thực hiện các hành động scale hệ thống (về dọc hoặc ngang), một câu hỏi không thể bỏ qua đó là:
Chúng ta đã tunning hệ thống tới mức tối ưu chưa?
Trả lời cho câu hỏi này thường rất khó. Tuy nhiên, viễn cảnh tốt đẹp nhất hướng đến là “Tunning hệ thống tốt nhất có thể”.
Việc profiling danh sách các công việc mà hệ thống cần thực hiện để đáp ứng một tính năng (API), kèm theo thời gian thực thi tương ứng sẽ giúp chúng ta dễ dàng tìm được bottle necks của ứng dụng. Liên tục đặt câu hỏi về việc:
- “Dữ liệu có thể cache không?”
- “Cache trong bao lâu là hợp lí?”
- “Có cần chủ động invalid cache không?”
Nếu đã làm hết các việc trên mà hệ thống vẫn không đáp ứng được lượng request như mong muốn, lúc này chúng ta hãy tính đến việc scale hệ thống.
Lặp lại việc stress test và audit report, scale up cho đến khi chúng ta đạt đến số lượng request mong muốn.
Tham khảo
- https://github.com/tsenart/vegeta
- https://thisdata.com/blog/load-testing-api-interfaces-with-go-and-vegeta/
- http://dygraphs.com/
- https://stackoverflow.com/questions/9750509/load-vs-stress-testing
- https://www.graylog.org/
Author: Khai Huynh